MobileNets v1模型解析
上一篇文章《RK3399上Tengine平台搭建 | Hey~YaHei!》中在RK3399上搭建了Tengine平台并试运行了MobileNet SSD网络,本文将为你解析MobileNets v1的实现思路。
下边分解过程是按自己理解画的图,如果理解有误欢迎指正~
论文:《MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications(2017)》
深度向卷积分解(Depthwise Separable Convolution)
基本思路
将普通卷积的过程分解为“滤波”和“组合”两个阶段——
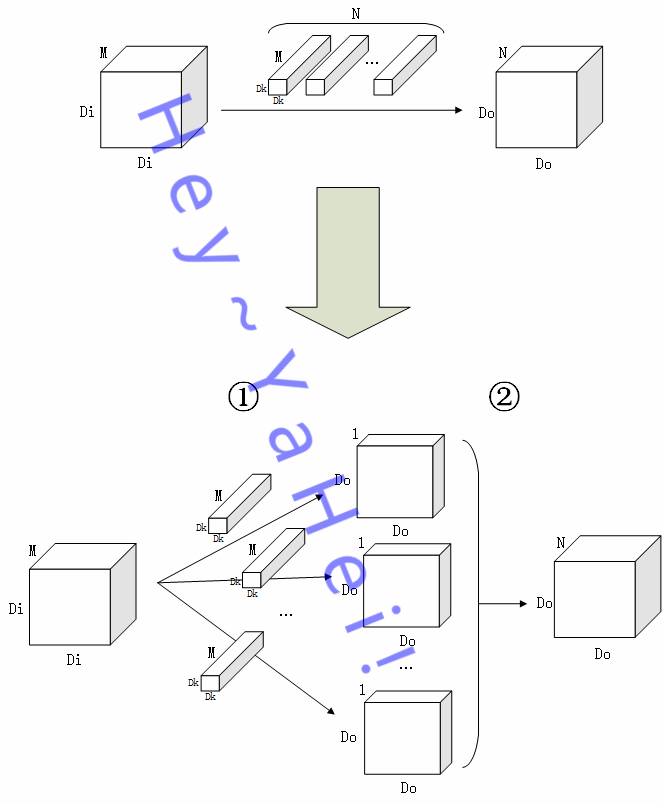
如上图,
假设 $M$ 通道输入图 $I$ 大小为 $D_I \times D_I$,经过一个核大小 $D_K \times D_K$ 的卷积层,最终输出一张大小为 $D_O \times D_O$ 的 $N$ 特征图 $O$
- ①阶段为“滤波”阶段,$N$ 个卷积核分别作用在图 $I$ 的每个通道上提取特征,最终输出 $N$ 张大小为 $D_O \times D_O$ 的单通道特征图;
- ②阶段为“组合”阶段,$N$ 张特征图堆叠组合起来,得到一张 $N$ 通道的特征图 $O$
更详细地,①过程还能进一步分解——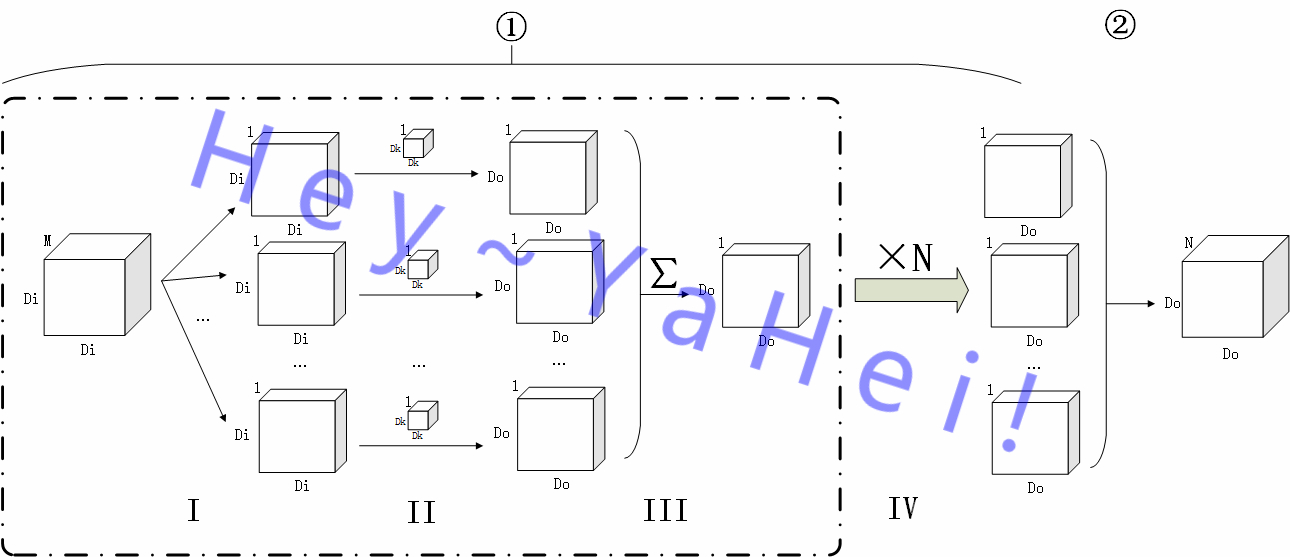
如上图,将①阶段进一步细分为 Ⅰ 到 Ⅳ 四个子阶段,
- Ⅰ 阶段,将原图 $I$ 按通道分离成 $\{ I_1, I_2, …, I_M \}$ 的 $M$ 张单通道图;
- Ⅱ 阶段,用M个卷积核 $K_m$ 对各个单通道图提取特征,分别得到一张大小为 $D_O \times D_O$ 的单通道特征图;
- Ⅲ 阶段,对 Ⅱ 阶段输出的 $M$ 张单通道特征图按通道堆叠起来然后“拍扁”(沿通道方向作加法操作),得到原图在该卷积核作用下的最终输出 $O_n$;
- Ⅳ 阶段,用另外 $N-1$ 个卷积核重复 Ⅱ 、 Ⅲ 阶段,得到 $N$ 张大小为 $D_O \times D_O$ 的单通道特征图
可以看到,传统的卷积中用 $N$ 个不同的卷积核不厌其烦地对原图进行特征提取来得到 $N$ 通道的输出,这其中必定从原图中提取到了大量的重复特征。有没有可能只用单个卷积核来做特征提取,最后依旧能输出多通道的特征图呢?这就是深度向卷积分解的核心思想。
观察①阶段中的第三个子阶段,该阶段将多张单通道特征图按通道堆叠起来之后“拍扁”,如果去掉这个“拍扁”的过程,其实就可以提取得到一张 $M$ 通道的特征图啦,再经过一个 $M$ 维空间到 $N$ 维空间的线性映射,就能够和普通的卷积操作一样得到一张 $N$ 通道的特征图 $O$。完整的卷积过程如下图所示——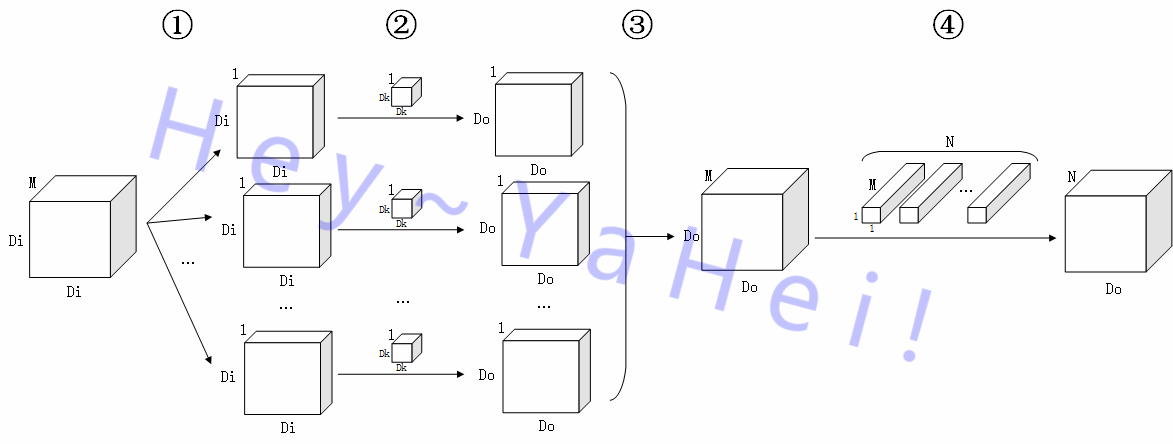
- 滤波Depthwise Convolution
①、②阶段与传统卷积①阶段的前两个阶段完全相同,③阶段比传统卷积①阶段的第三个阶段少了一个“拍扁”的过程,直接堆叠形成一张 $M$ 通道的特征图; - 组合Pointwise Convolution
④阶段用 $N$ 个 $1 \times 1$ 卷积核将特征图从 $M$ 维空间线性映射到 $N$ 维空间上
效率比较
假设 $M$ 通道输入图 $I$ 大小为 $D_I \times D_I$,经过一个核大小 $D_K \times D_K$ 的卷积层,最终输出一张大小为 $D_O \times D_O$ 的 $N$ 特征图 $O$
对于普通的卷积操作,
- 输出 $N$ 通道特征图需要 $N$ 个卷积核,故参数数量为 $M \times N \times D_K \times D_K$;
- 一个 $D_K \times D_K$ 的卷积核在原图的某个位置的某个通道上需要进行 $D_K \times D_K$ 次乘加操作,输出特征图大小为 $D_O \times D_O$,原图通道数量为 $M$,共有 $N$ 个不同的卷积核,故乘加操作数量为 $D_K \times D_K \times D_O \times D_O \times M \times N$
对于深度向分解后的卷积操作,
- 特征提取只使用了一个 $D_K \times D_K$ 的卷积核,组合过程为了作线性映射用了 $N$ 个 $1 \times 1$ 的卷积核,故参数数量为 $M \times N + M \times D_K \times D_K$;
- 特征提取过程只有一个卷积核,所以该过程乘加操作数量为 $D_K \times D_K \times D_O \times D_O \times M$。同样的,组合过程容易算得需要 $D_O \times D_O \times M \times N$ 次乘加操作。故乘加操作的总数量为 $D_O \times D_O \times M \times ( D_K \times D_K + N)$
总的来说,参数数量和乘加操作的运算量均下降为原来的 $\frac{1}{D_K^2} + \frac{1}{N}$,通常使用 $3 \times 3$ 的卷积核,也就是下降为原来的九分之一到八分之一左右。而从论文的实验部分来看,准确率也只有极小的下降。

模型结构
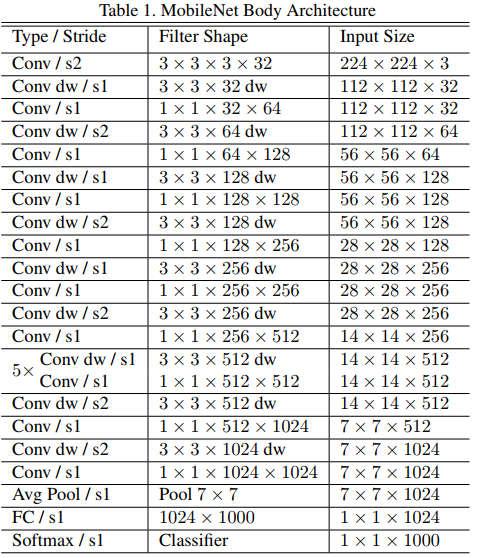
- 第一层使用普通的卷积层,最前端的特征提取非常重要,宁可存在重复的特征信息,也不该放掉;
- 随后是一系列的深度向分解卷积层,用于逐层次提取特征,用步长不为1的卷积替代池化做降采样,同时整体也满足通道加深,特征图分辨率降低的CNN一般特点;
- 最后也是常规的全局平均池化、全连接、Softmax;
- 每次卷积操作之后都紧跟一个BN层(在预测阶段可以被合并)和一个RELU层;

- 而且,深度向分解的卷积中绝大多数参数和运算都集中在 $1 \times 1$ 的pointwise卷积运算当中,这种运算恰恰是能够被
GEneral Matrix Multiply(GEMM)函数高度优化的(具体参见《深度学习小技巧(二):模型微调 - 高效的1x1卷积 | Hey~YaHei!》);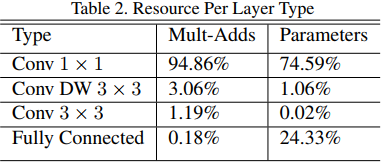
- 论文中还提到两个压缩模型的因子,分别用于输入图片分辨率收缩和特征通道数量收缩来进一步精简模型;
训练细节
- 小模型,不容易过拟合,不需要太多正则化策略和数据增强策略
- 参数数量少,可以为Depthwise Convolution加入一个很小的权重衰减甚至不需要权重衰减
本文介绍了MobileNets v1的主要思想——Depthwise Separable Convolution以及网络的完整结构,其实这一思想也不是MobileNet首创,在MobileNets v1之前Xception就已经提出这种思路。此外,MobileNets v1还是只是一个传统的结构,而且没有像Xception一样去RELU来避免卷积后通道下降非线性单元对特征信息造成的损失,在今年Google新发的MobileNets v2就分析和缓解这一问题,并且引入了类似ResNet的shortcut设计。
但,我们还是先一步步解剖好chuanqi305的MobileNets-SSD网络,所以暂时不就MobileNets v2的设计展开讨论,下篇文章将继续讨论目标检测框架SSD的设计——《SSD框架解析 | Hey~YaHei!》。