深度学习小技巧(二):模型微调
接着上一篇文章《深度学习小技巧(一):高效训练 | Hey~YaHei!》继续解读论文《Bag of Tricks for Image Classification with Convolutional Neural Networks(2018)》,论文中以ResNet为例提出了一些简单的微调技巧,并且取得了一定的成果。且不说准确率如何,论文中除了分析准确率有着怎样怎样的提升之外,还关注了产生了额外开销,并且通过分析、实验量化了这些开销,这是值得肯定的(比那些不考虑开销,盲目微调,通过牺牲很多速度来提高那一点点准确率的论文,不知道要高到哪里去!)
以ResNet为例
原始的ResNet模型可以参考《经典的CNN分类架构 - ResNet | Hey~YaHei!》,其核心在于应用了shortcut(原文称为skip connection)技术使得深层网络也能够被有效训练,具体细节这里就不再赘述。
ResNet v2
《Identity Mappings in Deep Residual Networks(2016ECCV)》对ResNetv1做了一些有效的改进,使得shortcut的通路更加“干净”,有利于信息的流通,不仅可以训练更深层的网络,而且使得ResNet的表现有了进一步的提升。
具体设计
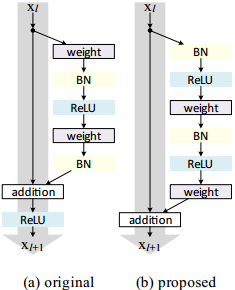
作者主要改变了ReLU和BN的位置,从而使得shortcut通路的信息流通更加顺畅——
先用数学符号定义残差网络
$$
\begin{aligned} \mathbf{y}_{l}=& h\left(\mathbf{x}_{l}\right)+\mathcal{F}\left(\mathbf{x}_{l}, \mathcal{W}_{l}\right) \\ & \mathbf{x}_{l+1}=f\left(\mathbf{y}_{l}\right) \end{aligned}
$$
其中,
$\mathbf{x}_{l}$ 是第l个残差单元的输入;
$\mathcal{W}_{l}=\left\{\mathrm{W}_{l, k}|_{1 \leq k \leq K}\right\}$ 是第l个残差单元的一系列权重;
$\mathcal{F}$ 表示残差单元的计算过程(不包含最后的ReLU);
$h\left(\mathbf{x}_{l}\right)=\mathbf{x}_{l}$ 表示shortcut的通路;
$f$ 表示激活函数
为了方便分析,我们先简化问题,使 $\mathbf{x}_{l+1}=f\left(\mathbf{y}_{l}\right) = \mathbf{y}_{l}$,则有
$$\mathbf{x}_{l+1}=\mathbf{x}_{l}+\mathcal{F}\left(\mathbf{x}_{l}, \mathcal{W}_{l}\right)$$
那么对任意L,能有
$$
\begin{aligned}
\mathbf{x}_{L} &= \mathbf{x}_{l}+\sum_{i=l}^{L-1} \mathcal{F}\left(\mathbf{x}_{i}, \mathcal{W}_{i}\right) \\
&= \mathbf{x}_{0}+\sum_{i=0}^{L-1} \mathcal{F}\left(\mathbf{x}_{i}, \mathcal{W}_{i}\right)
\end{aligned}
$$
对应地,反向传播时有
$$
\begin{aligned}
\frac{\partial \mathcal{E}}{\partial \mathbf{x}_{l}}
&= \frac{\partial \mathcal{E}}{\partial \mathbf{x}_{L}} \frac{\partial \mathbf{x}_{L}}{\partial \mathbf{x}_{l}} \\
&= \frac{\partial \mathcal{E}}{\partial \mathbf{x}_{L}}\left(1+\frac{\partial}{\partial \mathbf{x}_{l}} \sum_{i=l}^{L-1} \mathcal{F}\left(\mathbf{x}_{i}, \mathcal{W}_{i}\right)\right)
\end{aligned}
$$
如此一来,残差单元在前向传播时能直接获得浅层信息,而且在反向传播时不容易出现梯度消失,这也是ResNet有效的主要原因。
即使如此,ResNet v1在超过200层时依旧会出现明显的过拟合现象~首先要观察到,前述的分析中为简化问题忽略了激活函数的作用,而v2则指出激活函数妨碍了shortcut通路的信息流通,并尝试改变激活的位置来使得通路更加干净。
保证shortcut通路通畅的重要性
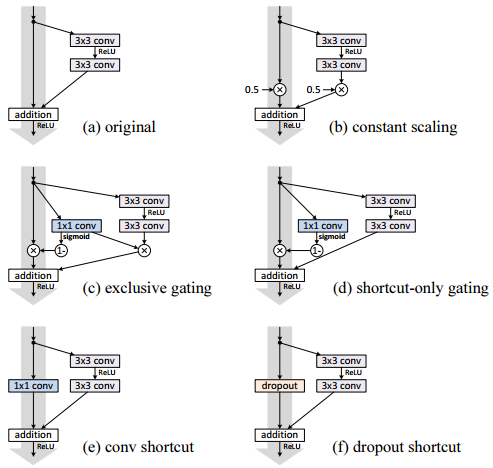
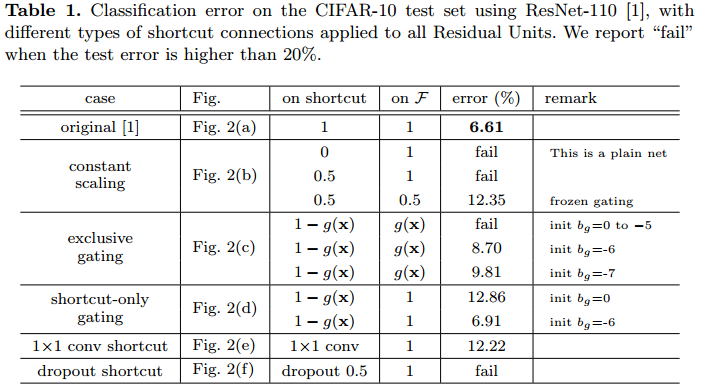
作者设计了如下实验,分别为shortcut通路引入各种干扰——比如缩放、门控、丢弃等,发现模型的表现明显下降,这证明了确保shortcut通路通常的重要性。
改变激活的位置
作者实验了各种激活的位置,得到了更好的设计方式
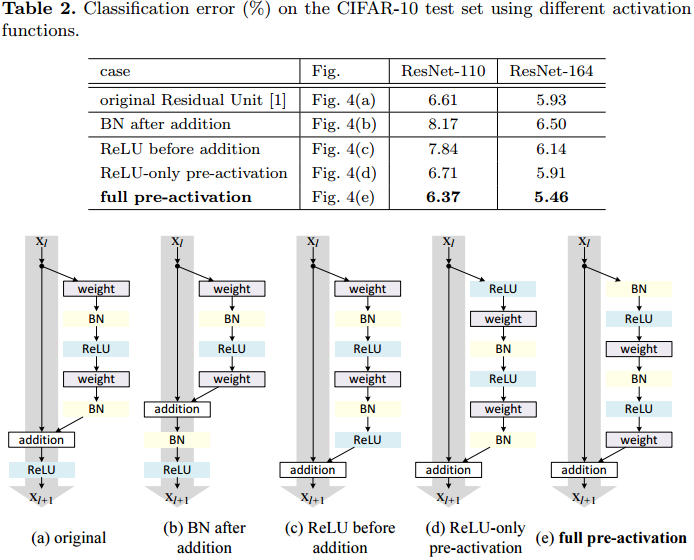
- b将BN也放到shortcut通路上,使shortcut通路更加复杂化,模型表现变差
- c把ReLU提到残差通路上,虽然shortcut通路变得干净,但做addition时残差均非负,特征的数值随着网络加深只会一味地增大,不利于学习特征提取
- d把ReLU提到卷积之前,与v1的表现差不多
- e把BN和ReLU都提到卷积之前,模型表现明显要比v2更好
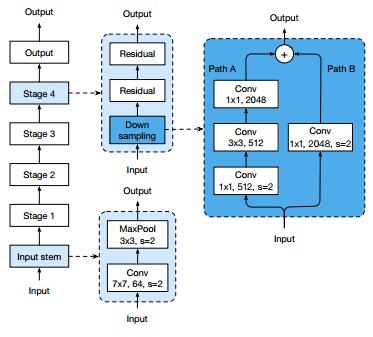
改进1:推迟下采样
该改进方法最初是在Torch上提出的,目前这一改进也已经被广泛地应用。
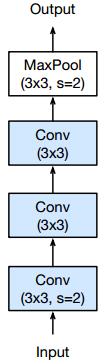
首先观察原始模型的下采样模块——
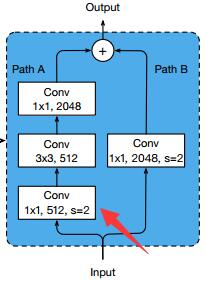
其PathA依次经过
1. 1x1的卷积,完成通道的收缩,并且步长为2以实现下采样
2. 3x3的卷积,通道数量不变,主要用于提取特征
3. 1x1的卷积,完成通道的扩张
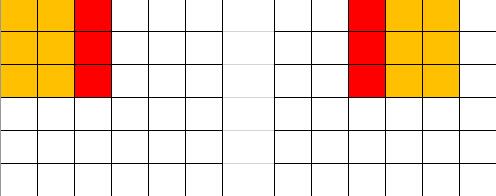
其中第一个卷积用来作为下采样,所以步长设为了1——但你仔细想想会发现,核大小1x1、步长2的卷积会造成3/4的信息丢失!以6x6的特征图为例,如下图所示,只有红色部分的信息能够传递到下一层去,非红色部分均不参与卷积计算。

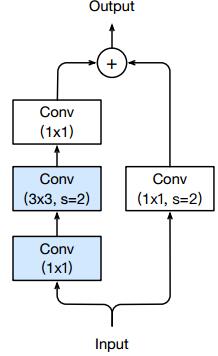
由此可见,在1x1的卷积层作下采样是不明智的,更好的做法是把下采样过程挪到3x3的卷积上,如下图所示,由于卷积核宽度大于步长,卷积核在移动过程中能够遍历输入特征图上的所有信息(甚至还能有重叠):
下采样模块就变为——
改进2:拆解大核卷积
如《卷积神经网络CNN - 卷积层(Conv) | Hey~YaHei!》所述,大核卷积层可以由多层小核卷积替代实现,这不仅可以减少参数,还能加深网络深度以增加网络容量和复杂度。
Inception也早在《Rethinking the Inception Architecture for Computer Vision(2015)》一文中对Inceptionv1做出改进,分别用三个和两个3x3卷积的级联去替代7x7和5x5的卷积。
这一技巧同样适用于ResNet——
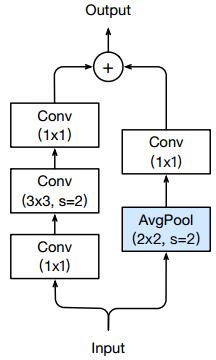
改进3:用平均池化替代1x1卷积做下采样
下采样模型的PathA和PathB都需要做下采样才能正确地加和,改进1只针对PathA做了改进,其实PathB也用了1x1的卷积做下采样。为此,论文《Bag of Tricks for Image Classification with Convolutional Neural Networks(2018)》用平均池化接替了PathB中的降采样工作:
实验结果
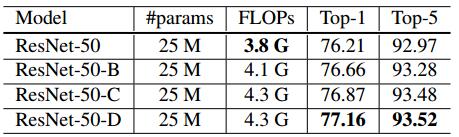
其中A、B、C、D分别代表原始、改进1、改进2、改进3的模型。
经过改进之后,最终的ResNet-50-D准确率提高了0.95%。但也不得不承认,以上的改进都增加了模型的运算复杂度,FLOPs增加了约13%,但实测速度只下降了3%。
关于FLOPs和实测速度
你可能会意外,为什么运算量明明增加了13%,可实测速度却只下降了3%呢??
多分支网络
首先要注意到,ResNet由于应用了shortcut技术,相比于传统的直筒式网络增加了分支,不同分支是可以并行计算的,而计算FLOPs时却是把不同分支的运算量依次累加起来。
高效的1x1卷积
早在《MobileNets v1模型解析 | Hey~YaHei!》一文中就提及过——
深度向分解的卷积中绝大多数参数和运算都集中在 1×1 的pointwise卷积运算当中,这种运算恰恰是能够被 GEneral Matrix Multiply(GEMM) 函数高度优化的。
为什么1x1卷积能够被高度优化?首先要先从卷积计算的实现讲起——
卷积的原理
详细原理可以参阅《卷积神经网络CNN - 卷积层(Conv) | Hey~YaHei!》和《5.1二维卷积层 | 动手学深度学习》。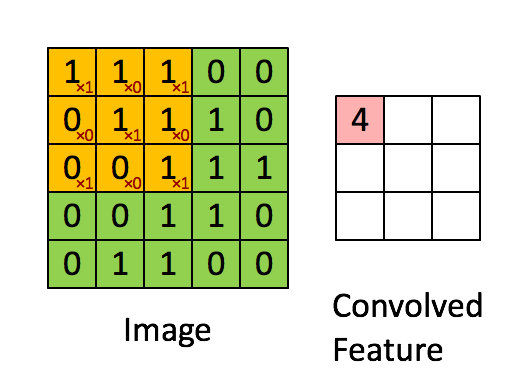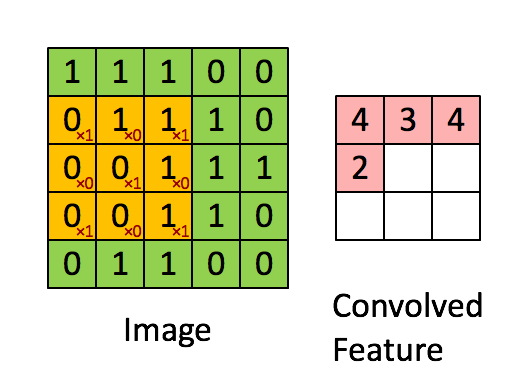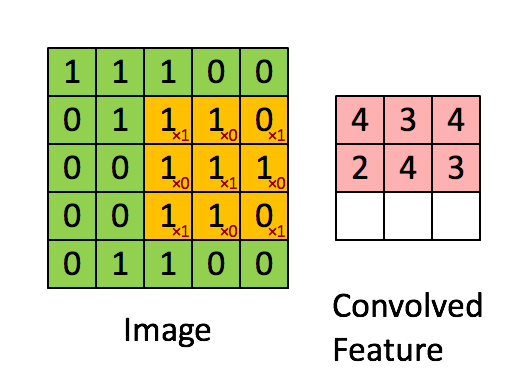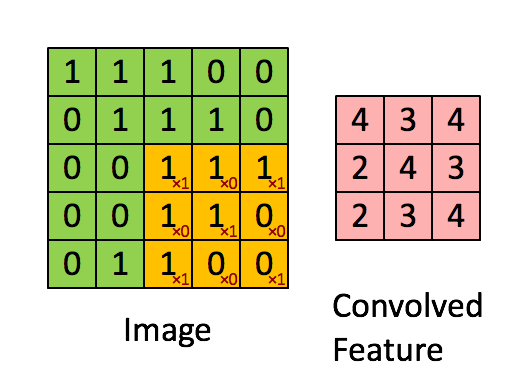
首先考虑3x3的单通道特征图,以及k2s1的卷积核——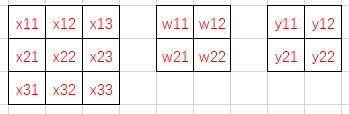
按照卷积计算,
$$y_{11} = w_{11}x_{11} + w_{12}x_{12} + w_{21}x_{21} + w_{22}x_{22}$$
$$y_{12} = w_{11}x_{12} + w_{12}x_{13} + w_{21}x_{22} + w_{22}x_{23}$$
$$y_{21} = w_{11}x_{21} + w_{12}x_{22} + w_{21}x_{31} + w_{22}x_{32}$$
$$y_{22} = w_{11}x_{22} + w_{12}x_{23} + w_{21}x_{32} + w_{22}x_{33}$$
按照“行先序”,特征图和卷积核在内存中是这样排列的——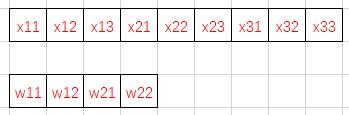
我们用不同的颜色标注出卷积计算中的访存过程(相同颜色的数据相乘)——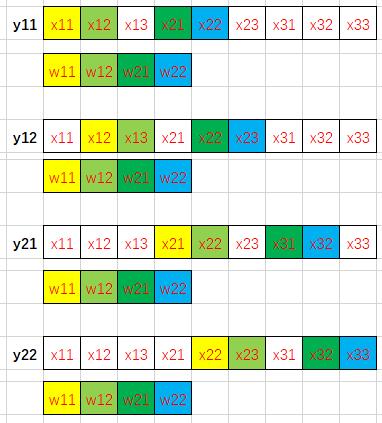
众所周知,由于程序的局部性原理(通常相邻代码段会访问相邻的内存块),现代处理器通常会按块从内存中读取数据到高速缓存中以缓解访存速度和计算速度的巨大差异导致的“内存墙”问题。换句话说,如果计算需要从内存中读取x12的数据,那么往往相邻的x11、x13等数据也会被一起读取到高速缓存上,当下次计算需要用到x11或x13时处理器就可以快速地从高速缓存中取出数据而不需要从内存中调取,大大提高了程序的速度。
注:L1缓存的读取速度是RAM的50-100倍!(数据来源:《计算机体系结构:量化研究方法》)
而从上边展示出来的访存过程中可以看到,直接对于特征图数据的访问过程十分散乱,直接用行先序存储的特征图参与计算是非常愚蠢的选择。
因此深度学习框架往往通过牺牲空间的手段(约扩增$K \times K$倍),将特征图转换成庞大的矩阵来进行卷积计算,这就是常说的im2col操作。
im2col
参考:
《im2col的原理和实现 | CSDN, dwyane12138》
《在Caffe中如何计算卷积? | 知乎, 贾扬清》
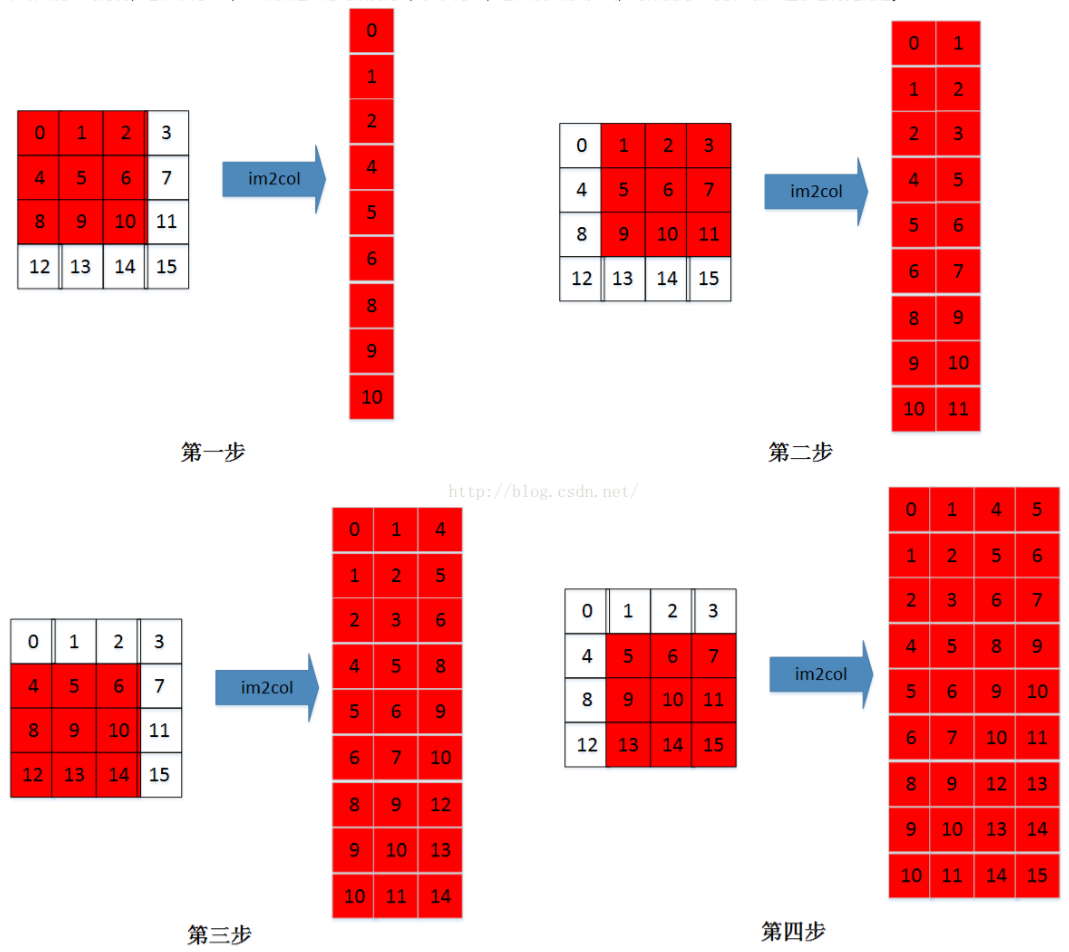
其实思路非常简单:把每一次循环所需要的数据都排列成列向量,然后逐一堆叠起来形成矩阵(按通道顺序在列方向上拼接矩阵)。
比如$C_i \times W_i \times H_i$大小的输入特征图,$K \times K$大小的卷积核,输出大小为$C_o \times W_o \times H_o$,
输入特征图将按需求被转换成$(K*K)\times(C_i*W_o*H_o)$的矩阵,卷积核将被转换成$C_o\times(K*K)$的矩阵,调用GEMM库两矩阵相乘也就完成了所谓的卷积计算。由于按照计算需求排布了数据顺序,每次计算过程中总是能够依次访问特征图数据,迎合了局部性原理,极大地提高了计算卷积的速度!
特别的1x1
回到1x1的卷积,它的im2col非常特殊——其原始存储结构跟im2col的重排列矩阵是完全相同的!!也就是说,1x1卷积甚至不需要im2col的过程,拿起来就能直接算,节省了数据重排列的时间和空间,所以哪怕是在相同FLOPs的前提下,1x1卷积也要比3x3卷积快速、高效得多。
当然,这是建立在局部性原理和冯诺依曼结构的基础之上,对于非冯结构的计算体系可能就不适用了。
这也是为什么MobileNet在论文最后要大肆鼓吹说他94.86%的运算量都集中1x1的卷积运算上,它的快速可不仅仅体现在“少参数,少运算量”上!
同理,前文中改进1和改进3看似增加了很多运算量,但这些运算量都是负担在1x1卷积上的,这就使得实测速度的下降远没有运算量增加那么明显!