经典的CNN分类架构
BGM:《GOSICK》ED2
从原文《卷积神经网络CNN | Hey~YaHei!》抽取出来;
参考:
- 《Hands-On Machine Learning with Scikit-Learn and TensorFlow(2017)》Chap13
《Hands-On Machine Learning with Scikit-Learn and TensorFlow》笔记 - 《卷积神经网络——深度学习实践手册(2017.05)》
CNN的典型组合方式是,以 卷积层+激活函数(一般是relu)+池化层 作为一组操作;
一张图片经过若干组这样的操作的stack之后,变得越来越小,同时越来越深(feature map越来越多);
在stack的顶层,经过一个常规的前馈神经网络(由若干个带激活的全连接层组成)后产生预测结果(通常经过一个softmax层)——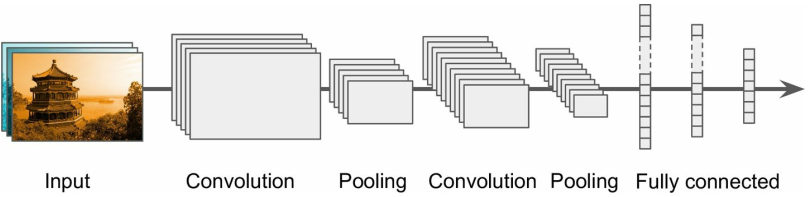
LeNet-5
经典的CNN框架,1998年由Yann LeCun提出,被广泛地应用于手写体数字识别(MNIST);
详细配置: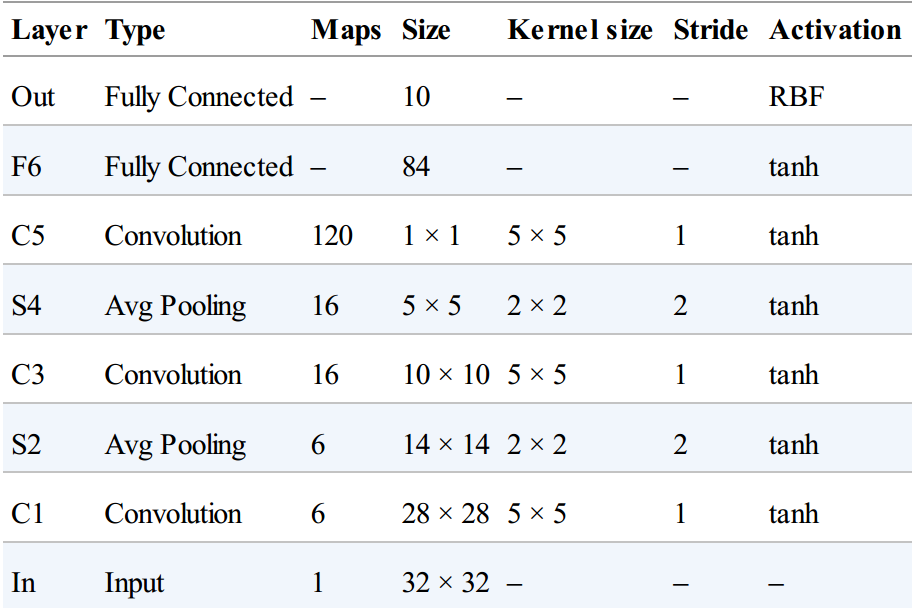
- MNIST数据为 $28 \times 28$ ,LeNet-5将其填零补充到 $32 \times 32$ 并在投喂给网络前进行归一化;
而其他层不再进行padding,所以可以看到每经过一层,图片就发生一次萎缩 - 平均池化层除了对输入进行平均之外,还经过一次仿射变换(缩放因子、偏置项都作为可学习的参数),并且在输出前经过一次激活
- C3层的神经元只与S2层的3到4个输出连接
- Out层不是简单的将输入和权重进行点乘,而是计算输入和权重的欧式距离的平方
而现在更好的方式是使用交叉熵
AlexNet
论文:Imagenet Classification with Deep Convolutional Neural Networks(2012)
赢得2012年的ImageNet ILSVRC比赛;
与LeNet-5很像,只是更大更深(约60万个参数);
他的突出成就是首次连续叠加卷积层而不是在每个卷积层之间插入池化层
详细配置: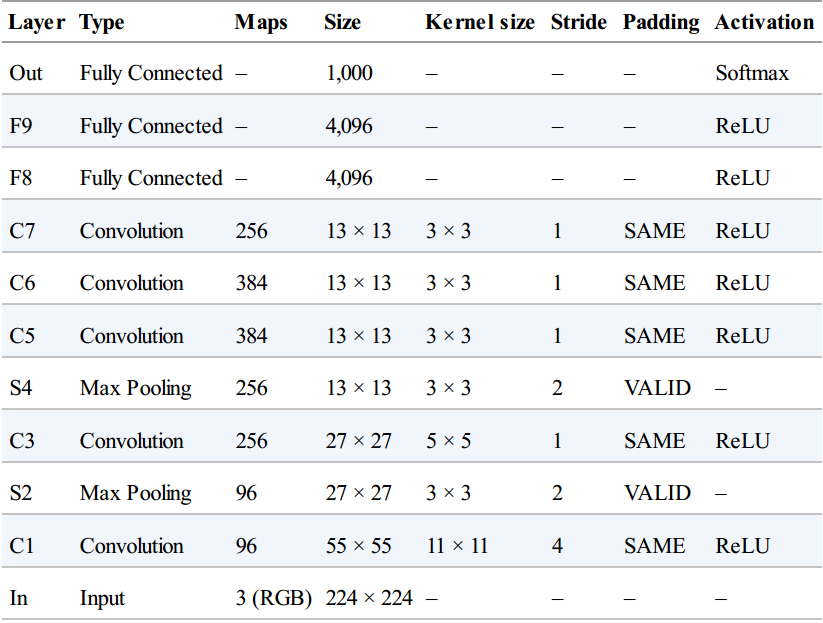
- 加入了一些正则化技术
- 为F8、F9加入dropout(dropout rate为50%)
- 数据增强(随机平移图片、水平翻转、改变光照条件)
- 在C1、C3层的激活函数之后紧跟一个局部响应归一化操作(Local Response Normalization, LRN)
使得强烈激活的神经元在相邻特征图的相同位置上的神经元被抑制(仿生);
这促进不同的特征图得到差异化,能够关注到不同的特征。- LRN的具体操作如下:
$$ b_i = a_i (k + \alpha \sum_{j = max(0, i - r/2)}^{min(i+r/2, f_n -1)} a_j^2)^\beta$$
其中,
$a_i, b_i$ 分别是LRN的第i个特征图输入、正则化输出;
$k, \alpha, \beta, r$ 是超参量,$k$ 称为偏置,$r$ 称为深度半径;
$f_n$ 是特征图的数量;
比如,当 $r=2$ 时,强烈激活的神经元会抑制他的上一个和下一个特征图中相同位置的神经元; - AlexNet采用的配置为 $r=2, \alpha = 0.00002, \beta = 0.75, k = 1$;
tensorflow提供了相应的local_response_normalization()操作;
- LRN的具体操作如下:
变种:ZFNet
论文:Visualizing and Understanding Convolutional Networks(2014)
2013年ILSVRC比赛冠军
VGG-Nets
论文:VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION(2015)
2014年ILSVRC亚军
详细配置: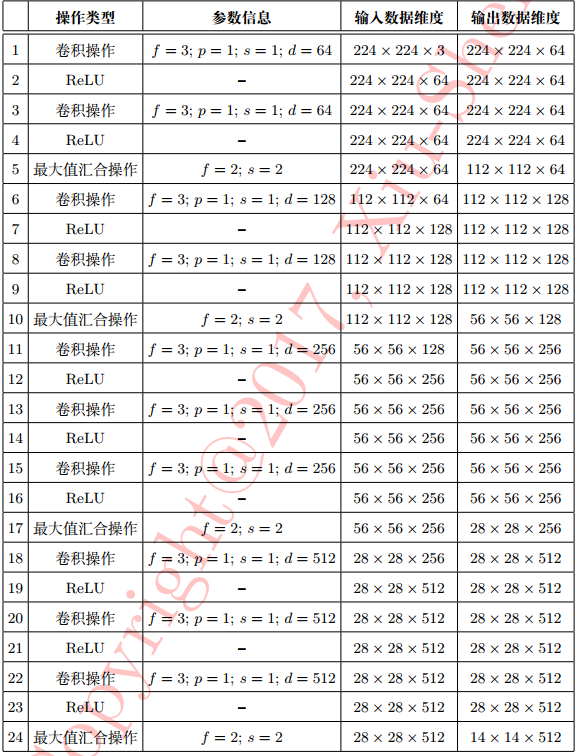
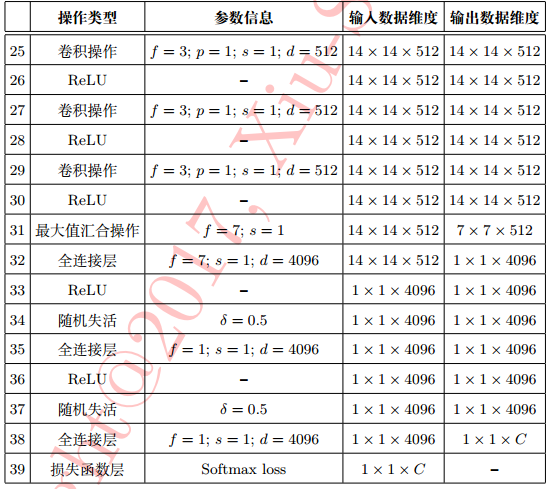
特点(相比AlexNet):
- 普遍使用小卷积核、以及一些保持输入大小的技巧
增加网络深度时确保各层输入大小随深度增加而不减小 - 网络卷积的通道数逐层增加($3 \to 64 \to 128 \to 256 \to 512$)
NIN(Network in Netwrok)
特点:
- 用多层感知机(多层FC和非线性函数的组合)替代线性卷积层
线性卷积层复杂度有限,层间映射只能将前层特征或输入简单地线性组合成后层特征;
高复杂度的多层感知机增加了卷积层的非线性能力,使得前层特征能有更多的复杂性和可能性映射到后层特征;
该思想随后也被Inception和ResNet借鉴 - 使用全局平均池化(Global Average Pooling)操作替代全连接层作为“分类器”
全局池化分别作用于每张特征图,最后映射到样本的真实标记;
此时每张特征图上的响应将很自然的对应到不同的样本类别,使得NIN更具可解释性;
该技术随后也被Inception借鉴
GoogLeNet
论文:Going Deeper with Convolutions(2015)
2014年ILSVRC冠军;
利用子网络inception模块,网络更加高效(大约只有AlexNet的十分之一),使得网络可以更深;
Inception模块: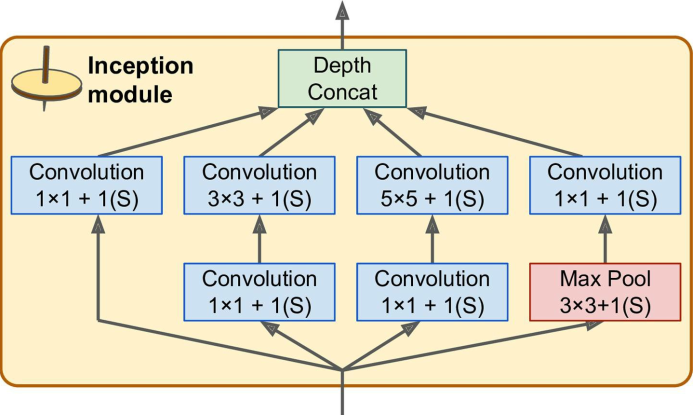
三层结构。其中,$3 \times 3 + 1(S)$ 表示核大小为3x3,步长为1,使用SAME填充方式;
- 每个卷积层都使用relu激活函数;
- 第二层分别使用了1x1,3x3,5x5的卷积核,这是为了模块在多尺度上捕捉特征
- 各个卷积层、池化层步长均为1,也就是说他们的输出大小与输入大小相同,这使得他们的输出可以被直接由Depth Concat层连接
- 1x1卷积层的作用:
- 降采样,1x1卷积层也可以称为瓶颈层(bottleneck layer),在3x3、5x5卷积层之前降采样,可以有效地减小计算开销
- 与3x3、5x5卷积层成对存在,使得图片被一个双层网络扫描而不是一个简单的线性分类器(啊?这在说啥)
Each pair of convolutional layers ([1 × 1, 3 × 3] and [1 × 1, 5 × 5]) acts like a single,
powerful convolutional layer, capable of capturing more complex patterns. Indeed, instead of
sweeping a simple linear classifier across the image (as a single convolutional layer does), this
pair of convolutional layers sweeps a two-layer neural network across the image
GoogLeNet框架:
包括9个Inception模块,每个卷积层都使用relu激活函数: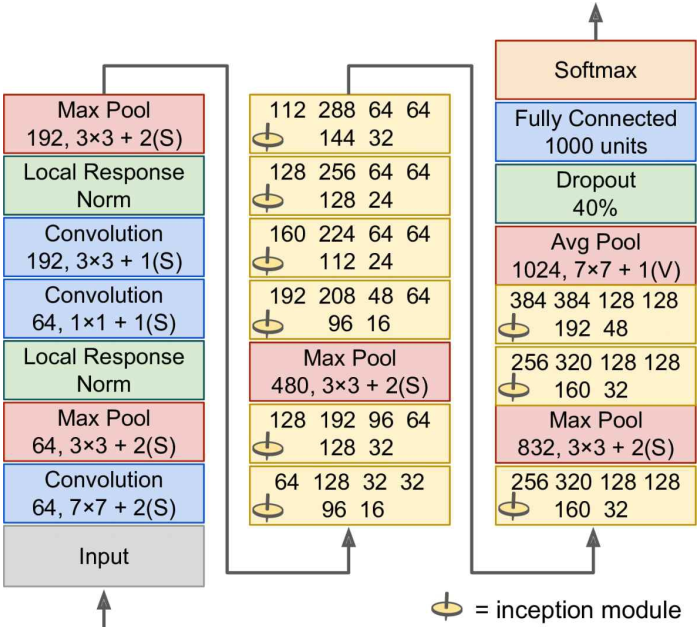
- 头两层(卷积层、池化层)步长均为2,相当于图片的长、宽都除以4,整体压缩为原来的十六分之一,以减少计算量
- LRN保证了前两层捕捉到多尺度的特征
- 1x1和3x3的卷积层对,构成一个比简单的线性分类器表现更好的卷积层
- 又一个LRN保证前层捕捉到多尺度的特征
- 步长为2的池化层进一步把图片压缩为原来的四分之一,减少计算量
- 接下来是连续的九个Inception模块,中间插入了两个最大池化层以进一步减少计算量(每一个池化层将图片压缩为四分之一)
- 平均池化层使用了不填充的步长为1的池化核,这种策略称为全局平均池化(Global Average Pooling)
这有效地令前层产生一个特征图,这个特征图实际上是每个预测分类的置信图(因为其他特征会在平均过程中被摧毁?);
这样一来,模型在输出前就不再需要多个全连接层,相当于减少了参数的数量并且减少过拟合 - 最后dropout层起正则化的作用,全连接层和softmax层产生预测结果
ResNet
论文:Deep Residual Learning for Image Recognition(2015)
其他:
- 机器之心 - 一文简述ResNet及其多种变体(2018) 【原文】
- Training Very Deep Networks(2015)
受LSTM中门机制的启发,提出高速公路网络,对前馈神经网络进行修正,使信息能够在多个神经网络层之间高效流动;这一思想也影响了ResNet网络
2015年ILSVRC冠军;
网络更深(152层),如此深的网络能够被训练主要得益于Skip Connections(或Shortcut Connections)技术;
残差学习(Residual Learning):
在常规网络的基础上,网络输出前增加一个与输入加和的操作;
这时网络不再直接训练目标函数 $h(x)$,而是训练 $f(x) = h(x) - x$;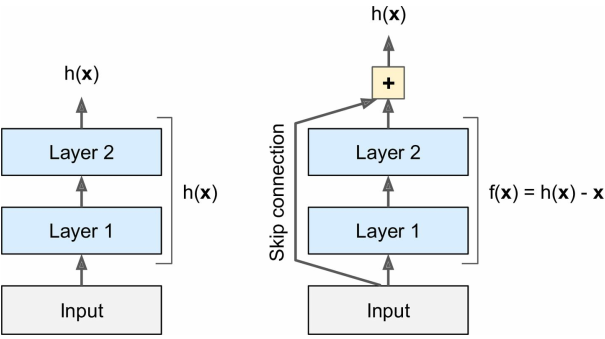
对于常规网络,权重被初始化为一个接近0的数,网络一开始只能输出一个非常接近于0的结果;
但是残差网络输出的却是一个接近输入的结果,而往往我们所要训练的目标函数跟这个输入还是比较接近的,这将大大加速我们的训练过程;
而且,如果加入了很多skip connections,网络可以在很早的时候就开始取得进步(有效地学习),即使中间有部分层还没开始进步也不影响,因为信号的传递很容易穿过整个网络;
深层残差网络可以看作是很多残差单元(Residual Unit, RU)的堆叠,每个残差单元是一个包含一个skip connection的小网络——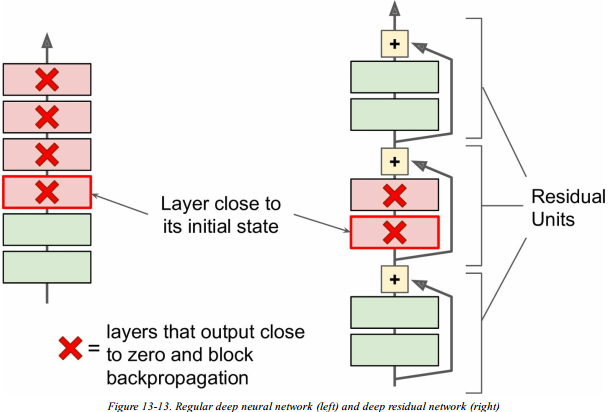
ResNet框架:
他的最底层和最顶层跟GoogLeNet差不多,ResNet-xxx中数字xxx代表模型中卷积层的数量;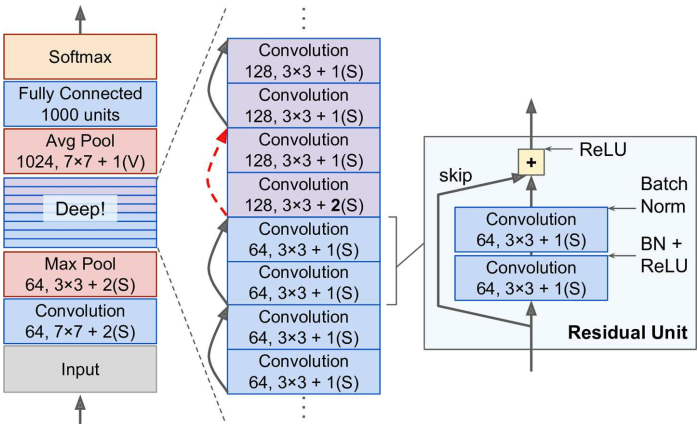
- 头两层与GoogLeNet完全相同
- 但ResNet没有LRN也没有1x1和3x3的卷积层对
- 接下来是一个深层的残差网络,由许多残差单元组成(每个残差单元包含两个卷积层以及BN层、relu激活函数、skip connection,步长为1、补零、保持大小)
每经过一定层数,图片会经过一个步长为2的卷积层而被压缩,然后接下来的残差单元的大小都增加一倍
此时这个残差单元的输入不能直接加到输出上(大小不一致),而应该在加和前让输入经过一个1x1步长2的卷积层——
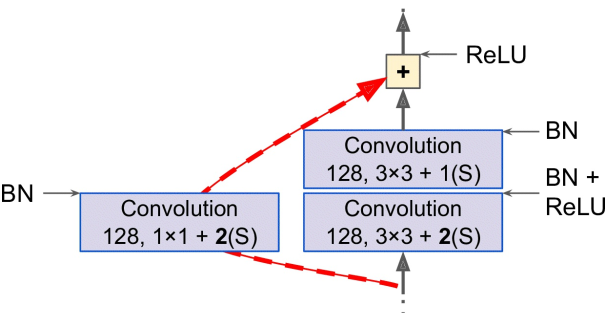
- 最后两层也与GoogLeNet完全相同,不过这里不需要dropout
各种不同深度的ResNet:
(只计算卷积层和全连接层,除去底层的卷积层和顶层的全连接层,不考虑每次倍增的时候多出来的1x1卷积层)
- ResNet-34
- 3个64输出的RUs
- 4个128输出的RUs
- 6个256输出的RUs
- 3个512输出的RUs
- ResNet-152
RU结构发生变化,使用三层卷积(1x1的64输出卷积层作为瓶颈层,然后一个3x3的64输出卷积层,再紧接一个1x1的 $4 \times 64=256$ 输出卷积层来恢复深度)- 3个256输出的新RUs
- 8个512输出的新RUs
- 36个1024输出的新RUs
- 3个2048输出的新RUs
趋势
网络越来越深,参数越来越少;
目前而言,ResNet兼具简单、表现出色两个特点;
2016年和2017年中国拿了第一,但是好像没有提出什么有趣的东西,是刷榜吗?
其他值得研究的框架——
- Inception-v4(2016):吸收兼并GoogLeNet和ResNet的思想,并提出网络inception-resnet-v1和inception-resnet-v2
- NASNet(2018):2017谷歌提的框架,准确率很诱人,但据说规模大的很,吐槽的人倒也不少
- MobileNets(2017):目前移动端应用地最多的、速度很快同时表现客观的一个网络,具体介绍可以参见《MobileNets v1模型解析 | Hey~YaHei!》
最后附一个tensorflow内置的常见框架模块及其预训练模型