MixConv:混合感受野的深度可分离卷积
继EfficientNet和CondConv之后,我们再来聊聊Google Brain的另一篇图像特征提取相关的论文《MixConv: Mixed Depthwise Convolutional Kernels(2019BMVC)》,作者采用类似inception的大小核混合卷积结果,再结合深度可分离卷积的特性,做到少量的额外代价即可提升卷积的特征提取能力。
混合感受野的卷积
MixConv的作者在MobileNet上做了几个简单实验,把原版的3x3卷积统一替换为更大的卷积,然后观察模型特征提取能力的变化——
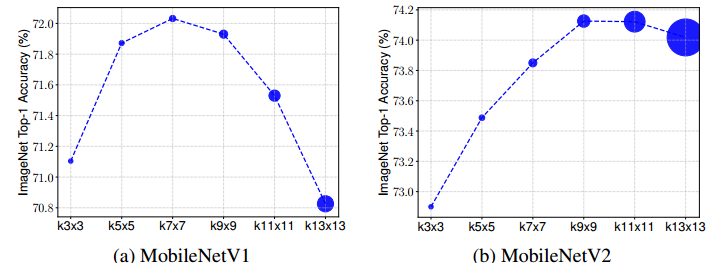
发现,随着卷积核的增大,其特征提取能力会随之增大,但超过某个值之后就反而会减小。并且指出,
- 大核卷积擅长提取大感受野特征,而小核卷积擅长提取小感受野特征
- 高感受野特征和小感受野特征是互补关系,并不是说大感受野特征一定比小感受野特征要好(可以考虑卷积核与特征图尺寸相当的极端情况)
- 如果能够混合不同感受野的特征,那么对于提高特征提取能力将会有所帮助
其实混合感受野的卷积早就在著名的inception上应用过,inception将输入分别投喂给不同的分支,每个分支采用不同大小的卷积核来提取出不同感受野的特征,最后将各个分支的结果连接起来作为输出。后来也出现了融合ResNet和Inception的Inception-ResNet网络。
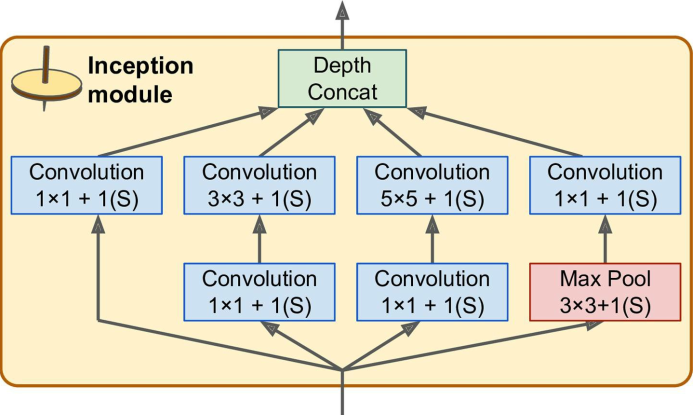
虽然混合感受野的特征确实有助于提高特征提取能力,但不得不承认,Inception模块需要付出不小的计算和存储代价!
然而有意思的是,因为深度可分离卷积的特性,在深度可分离卷积上采取混合感受野的代价会小的多——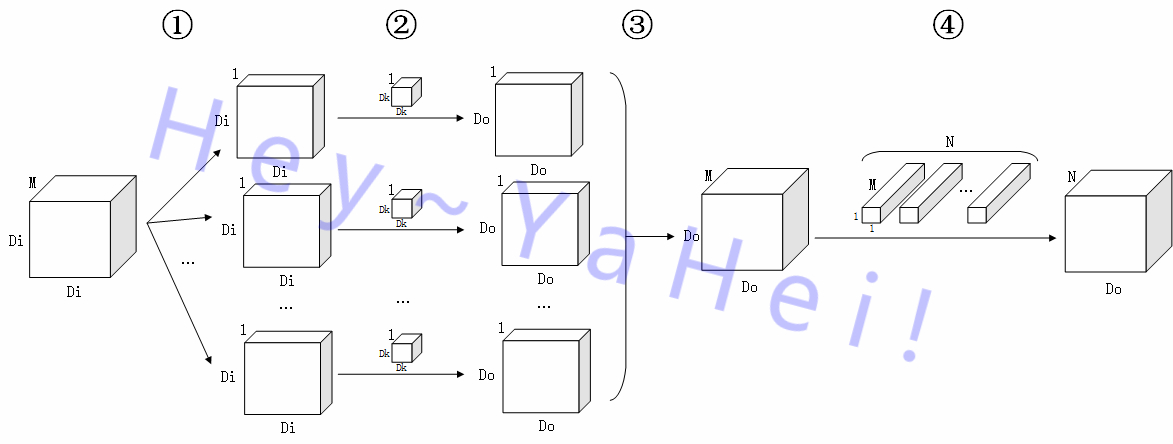
这是一个典型的深度可分离卷积,它将标准卷积拆解成一个num_groups==num_channels的DW卷积和一个1x1卷积级联的形式,前者对输入进行特征提取,后者对提取的特征进行组合从而映射到目标空间上去。(具体过程可以参考《MobileNets v1模型解析 - 深度向卷积分解 | Hey~YaHei!》,此处就不再赘述)
深度可分离卷积的参数和计算量主要集中在负责组合特征的1x1卷积上(比如MobileNetv1就有94.86%的计算量和74.59%的参数量集中在1x1卷积上,而3x3的DW卷积仅仅贡献了3.06%的计算量和1.06%的参数量),混合感受野只需要也只能作用在DW卷积上,所以总的来说,即使将深度可分离卷积改造成混合感受野的形式,也不会带来明显的额外计算、存储代价。
MixConv
MixConv并不像inception对整个输入特征图分别采用不同大小的核进行卷积,而是延续DW卷积本身的特性,将特征图按通道分割为多个组,每组采取不同大小的核进行卷积,最后再连接起来。
比如一个3x3的DW卷积,转换成一个3x3, 5x5, 7x7组合的混合感受野DW卷积,
(请原谅我这老土的配色)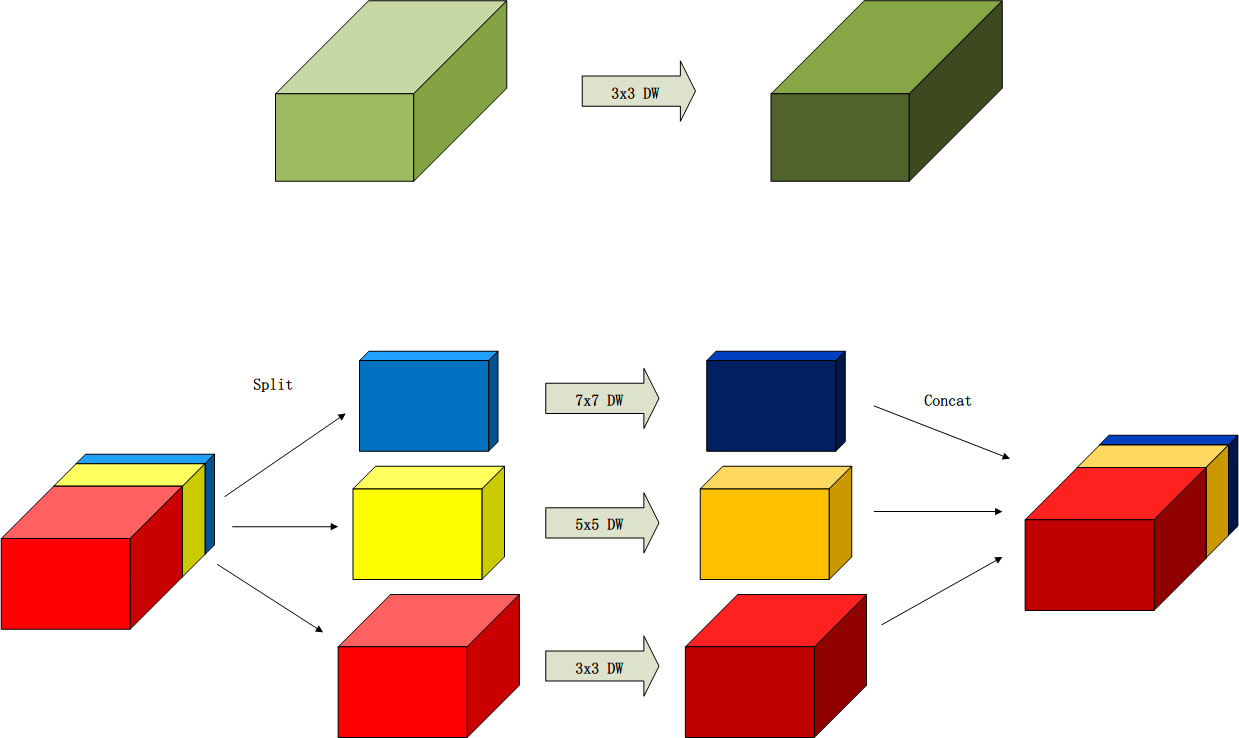
- 如何对输入特征图进行分组?
作者尝试了均匀划分和指数递增两种形式,均匀划分对不同大小的卷积核分配相同数量的通道,指数递减则考虑核大小对计算量的影响,将卷积按核大小排序(一般是采用3x3、5x5、7x7、9x9……),最小的核分得$n$通道,稍大的核分得$n \times 2^{-i}$通道。作者通过实验表明,指数递减的方案有更高效的特征提取效果 - 空洞卷积尽管能用更小的代价获得大的感受野,但因为分辨率的减小,其效果不如直接的大核卷积
- 因为深度可分离卷积将滤波和组合两个阶段拆开,滤波阶段输出的特征图虽然会按照感受野的大小有规律的分隔开,但组合阶段又会将他们的结果混合起来,不用担心不同感受野产生的特征图信息不能流通
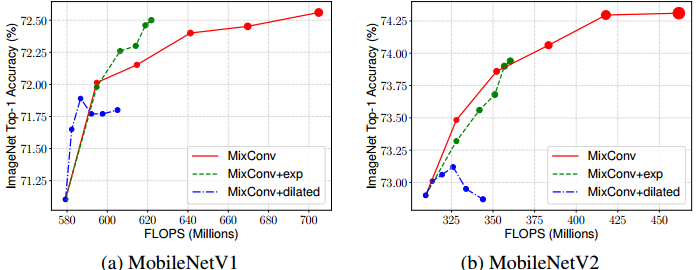
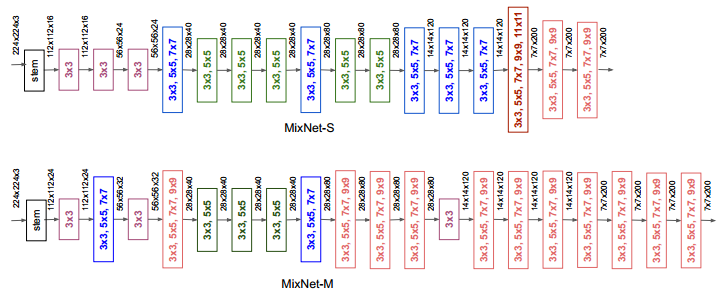
MixNet
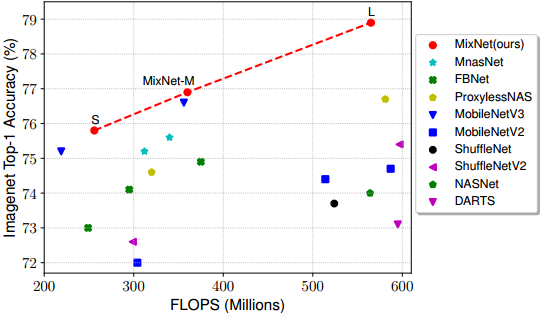
最后作者也跟EfficientNet一样,将这一新设计与NAS结合起来,搜索得到一个比较高效率的特征提取器MixNet,该模型甚至用上了9x9乃至11x11的大核卷积——