MobileNet全家桶
MobileNet自2017年发布v1以来就被广泛应用在移动端,随后又分别在2018年和2019年发布了v2和v3。去年《MobileNets v1模型解析 | Hey~YaHei!》一文中已经讨论过v1的主要贡献,趁着前阵子(已经是两个月前了其实)刚刚发布v3,不妨把整个MobileNet家族放在一起稍作讨论。
MobileNet v1
论文:《MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications(2017)》
主要贡献
- 用深度可分离卷积(DW卷积提取特征+点卷积组合特征)取代传统的卷积,大幅提升特征提取的效率
- 进而利用深度可分离卷积设计出高效的直筒式网络MobileNet
深度可分离卷积
基本思路
将普通卷积的过程分解为“滤波”和“组合”两个阶段——
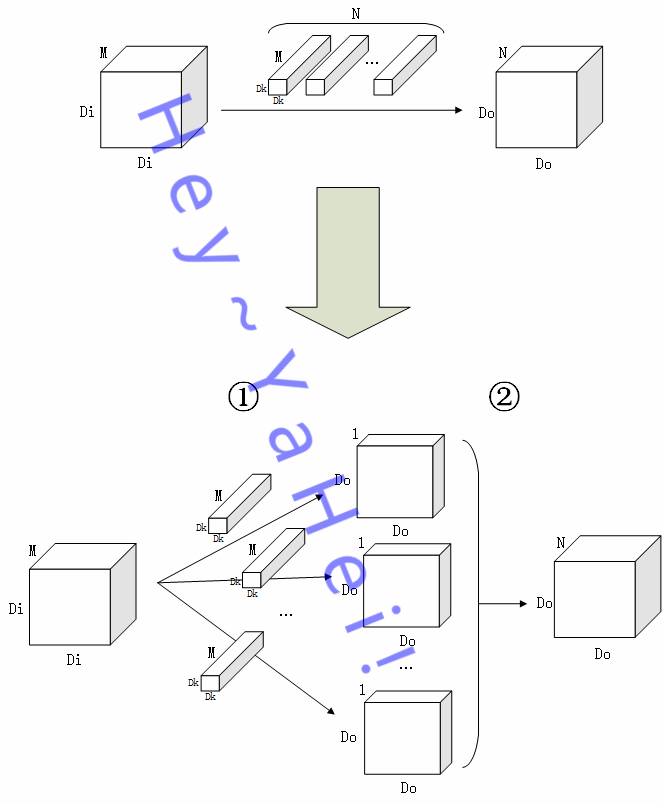
如上图,
假设 $M$ 通道输入图 $I$ 大小为 $D_I \times D_I$,经过一个核大小 $D_K \times D_K$ 的卷积层,最终输出一张大小为 $D_O \times D_O$ 的 $N$ 特征图 $O$
- ①阶段为“滤波”阶段,$N$ 个卷积核分别作用在图 $I$ 的每个通道上提取特征,最终输出 $N$ 张大小为 $D_O \times D_O$ 的单通道特征图;
- ②阶段为“组合”阶段,$N$ 张特征图堆叠组合起来,得到一张 $N$ 通道的特征图 $O$
更详细地,①过程还能进一步分解——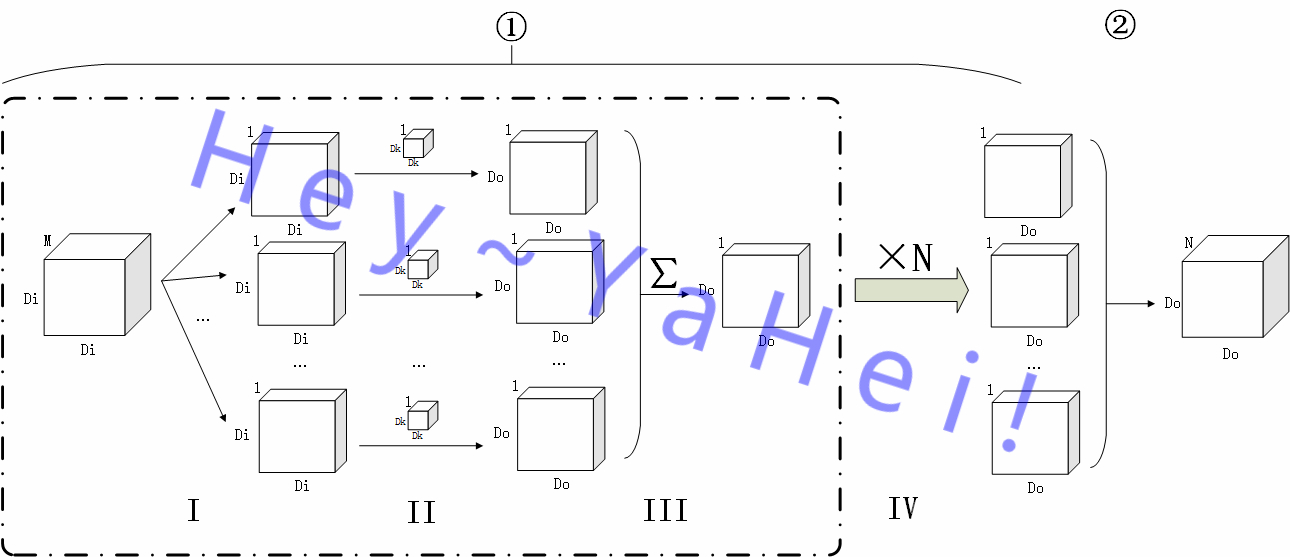
如上图,将①阶段进一步细分为 Ⅰ 到 Ⅳ 四个子阶段,
- Ⅰ 阶段,将原图 $I$ 按通道分离成 $\{ I_1, I_2, …, I_M \}$ 的 $M$ 张单通道图;
- Ⅱ 阶段,用M个卷积核 $K_m$ 对各个单通道图提取特征,分别得到一张大小为 $D_O \times D_O$ 的单通道特征图;
- Ⅲ 阶段,对 Ⅱ 阶段输出的 $M$ 张单通道特征图按通道堆叠起来然后“拍扁”(沿通道方向作加法操作),得到原图在该卷积核作用下的最终输出 $O_n$;
- Ⅳ 阶段,用另外 $N-1$ 个卷积核重复 Ⅱ 、 Ⅲ 阶段,得到 $N$ 张大小为 $D_O \times D_O$ 的单通道特征图
可以看到,传统的卷积中用 $N$ 个不同的卷积核不厌其烦地对原图进行特征提取来得到 $N$ 通道的输出,这其中必定从原图中提取到了大量的重复特征。有没有可能只用单个卷积核来做特征提取,最后依旧能输出多通道的特征图呢?——这就是深度向卷积分解的核心思路(或者换个角度,DW卷积就是分组卷积的一种极端情况)。
观察①阶段中的第三个子阶段,该阶段将多张单通道特征图按通道堆叠起来之后“拍扁”,如果去掉这个“拍扁”的过程,其实就可以提取得到一张 $M$ 通道的特征图啦,再经过一个 $M$ 维空间到 $N$ 维空间的线性映射,就能够和普通的卷积操作一样得到一张 $N$ 通道的特征图 $O$。完整的卷积过程如下图所示——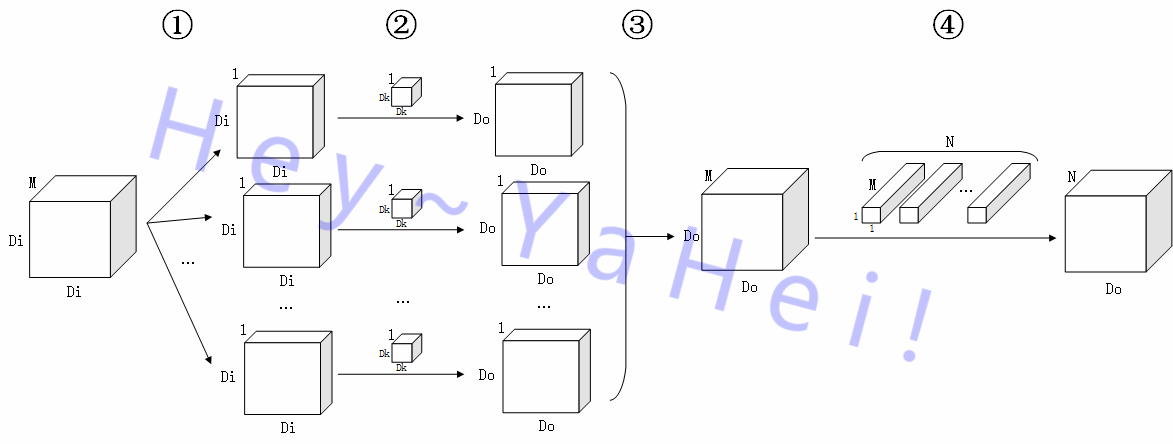
- 滤波Depthwise Convolution
①、②阶段与传统卷积①阶段的前两个阶段完全相同,③阶段比传统卷积①阶段的第三个阶段少了一个“拍扁”的过程,直接堆叠形成一张 $M$ 通道的特征图; - 组合Pointwise Convolution
④阶段用 $N$ 个 $1 \times 1$ 卷积核将特征图从 $M$ 维空间线性映射到 $N$ 维空间上
效率比较
假设 $M$ 通道输入图 $I$ 大小为 $D_I \times D_I$,经过一个核大小 $D_K \times D_K$ 的卷积层,最终输出一张大小为 $D_O \times D_O$ 的 $N$ 特征图 $O$
对于普通的卷积操作,
- 输出 $N$ 通道特征图需要 $N$ 个卷积核,故参数数量为 $M \times N \times D_K \times D_K$;
- 一个 $D_K \times D_K$ 的卷积核在原图的某个位置的某个通道上需要进行 $D_K \times D_K$ 次乘加操作,输出特征图大小为 $D_O \times D_O$,原图通道数量为 $M$,共有 $N$ 个不同的卷积核,故乘加操作数量为 $D_K \times D_K \times D_O \times D_O \times M \times N$
对于深度向分解后的卷积操作,
- 特征提取只使用了一个 $D_K \times D_K$ 的卷积核,组合过程为了作线性映射用了 $N$ 个 $1 \times 1$ 的卷积核,故参数数量为 $M \times N + M \times D_K \times D_K$;
- 特征提取过程只有一个卷积核,所以该过程乘加操作数量为 $D_K \times D_K \times D_O \times D_O \times M$。同样的,组合过程容易算得需要 $D_O \times D_O \times M \times N$ 次乘加操作。故乘加操作的总数量为 $D_O \times D_O \times M \times ( D_K \times D_K + N)$
总的来说,参数数量和乘加操作的运算量均下降为原来的 $\frac{1}{D_K^2} + \frac{1}{N}$,通常使用 $3 \times 3$ 的卷积核,也就是下降为原来的九分之一到八分之一左右。而从论文的实验部分来看,准确率也只有极小的下降。

模型结构
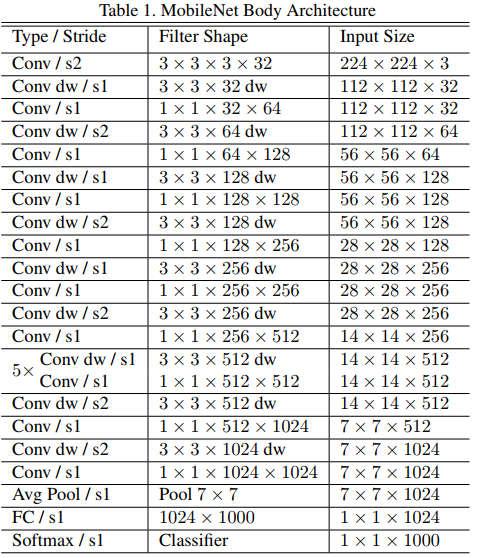
- 第一层使用普通的卷积层,最前端的特征提取非常重要,宁可存在重复的特征信息,也不该放掉;
- 随后是一系列的深度向分解卷积层,用于逐层次提取特征,用步长不为1的卷积替代池化做降采样,同时整体也满足通道加深,特征图分辨率降低的CNN一般特点;
- 最后也是常规的全局平均池化、全连接、Softmax;
- 每次卷积操作之后都紧跟一个BN层(在预测阶段可以被合并)和一个RELU层;

- 而且,深度向分解的卷积中绝大多数参数和运算都集中在 $1 \times 1$ 的pointwise卷积运算当中,这种运算恰恰是能够被
GEneral Matrix Multiply(GEMM)函数直接实现而不需要经过im2col或im2row的;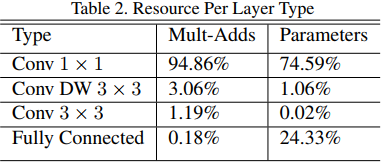
- 论文中还提到两个压缩模型的因子,分别用于输入图片分辨率收缩和网络宽度收缩来进一步精简模型;
- 由于MobileNet本身为小模型,不容易过拟合,故不需要过多的正则化策略和数据增强策略;且Depthwise Convolution参数数量比较少,只需要加入一个很小的权重衰减甚至可以不需要权重衰减
MobileNet v2
论文:《MobileNetV2: Inverted Residuals and Linear Bottlenecks(2018)》
主要贡献
- 取消通道收缩时的激活层:通道收缩时使用非线性激活会带来信息丢失
- 将relu改为relu6以限制激活的输出范围
- 引入反残差结构:MobileNet本身通道数量较少,引入“通道扩增-特征提取-通道收缩”的反残差结构有助于提高特征提取的能力
通道收缩时使用非线性激活带来信息丢失
用一个随机矩阵$T$,将一个初始的二维螺旋映射到一个$n$维空间后,经过一个非激活单元ReLU,再由$T^{-1}$反映射回二维空间。可以观察到,当n比较小(如n=2,3)时,反映射后的图形已经完全不像一个螺旋,出现明显的信息丢失:而当n比较大时,由于足够的冗余信息的存在,可以有效抵抗非线性单元带来的信息丢失:
反残差结构
v2参考了resnet,引入了shortcut设计,但不同的是:
- resnet采用“通道收缩-特征提取-通道扩增”的残差结构,对输入特征进行压缩,也减少了特征提取的参数量和计算量;
- 而MobileNet本身模型就不大,采用了相反的“通道扩增-特征提取-通道收缩”的反残差结构,以提高特征提取的能力
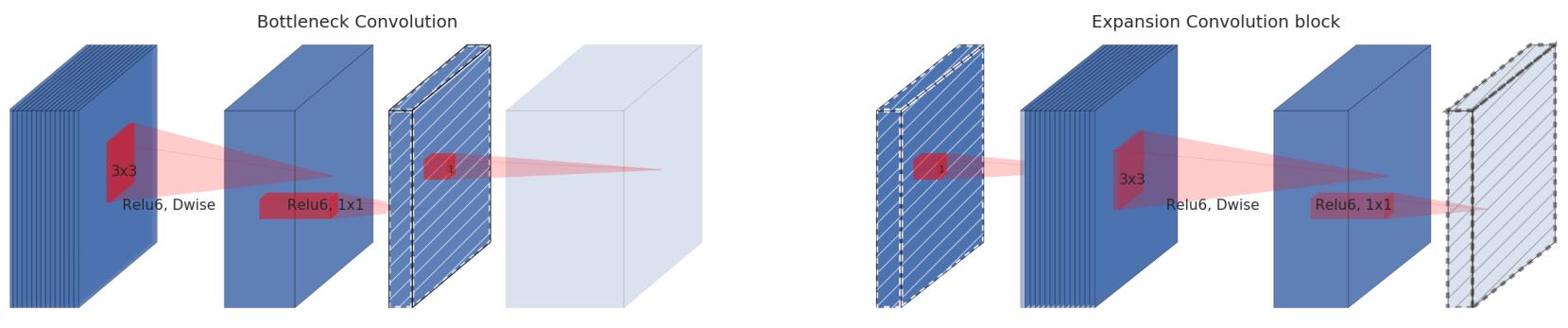
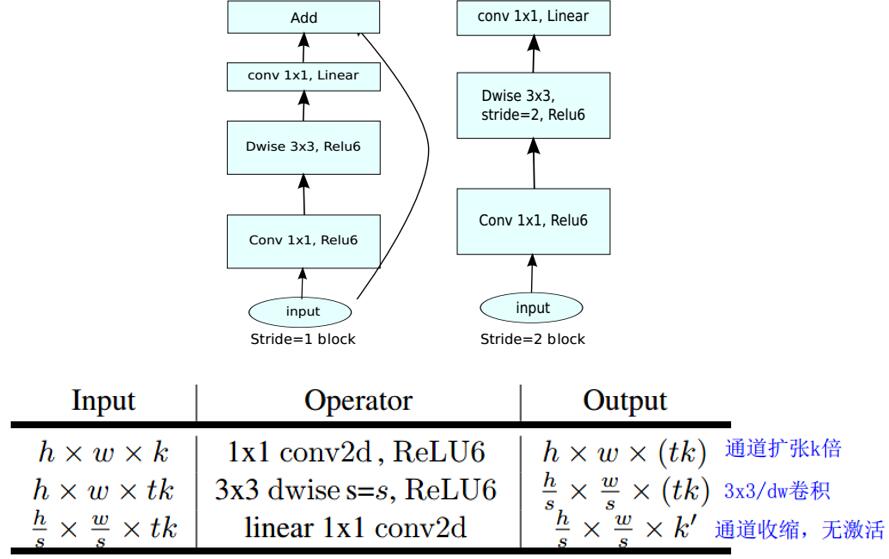
同时可以看到,与残差结构不同,反残差结构在elt+的输入都是通道扩增前的小通道特征图,可以说对带宽是比较友好的。
对于通道扩增的倍数,论文里建议是取5-10,如MobileNet v2里取$t=6$。
模型结构
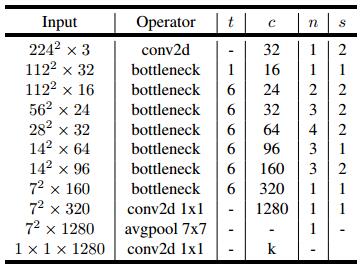
MobileNet v3
论文:《Searching for MobileNetV3(2019)》
主要贡献
- 用NAS搜索整体的网络架构
- 用NetAdapt搜索合适的网络宽度
- 引入注意力机制的SE模块
- 引入h-swish激活函数
网络搜索
正如论文标题所示,MobileNet v3的结构主要是通过Network Architecture Search(NAS)和NetAdapt搜索出来的。不过也有手工调整的部分,比如最后一个stage,作者将全局平均池化提前,并取消其中繁冗的特征提取、通道收缩过程,从而进一步提高的模型的效率。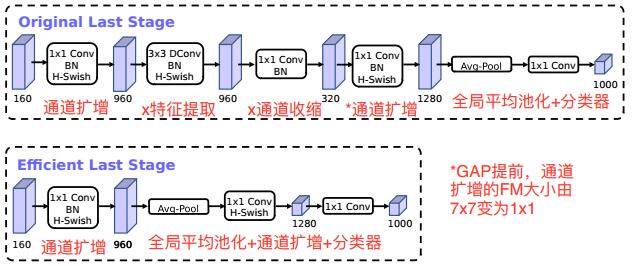
注意力机制:SE模块
v3引入了《Squeeze-and-Excitation Networks(2017)》的SE模块,通过全连接层对全局平均池化后的特征图进行通道重要性的评估,并将权重应用到特征图的通道上。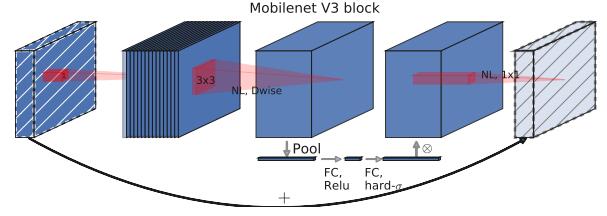
h-swish激活函数
《Sigmoid-weighted linear units for neural network function approximation in reinforcement learning(2017)》提出了新型激活函数swish并取得不错的效果——
$$swish(x) = x \cdot \sigma(x)$$
其中$\sigma(\cdot)$为sigmoid函数,
$$\sigma(x)=\frac{1}{1+e^{-x}}$$
不过sigmoid函数的指数运算终究太麻烦了,于是v3提出了hard-swish,通过分段函数ReLU6和相应的线性变换来近似sigmoid函数:
$$\text{h-swish}(x) = x \cdot \frac{ReLU6(x+3)}{6}$$
sigmoid和h-sigmoid、swish和h-swish的比较如下: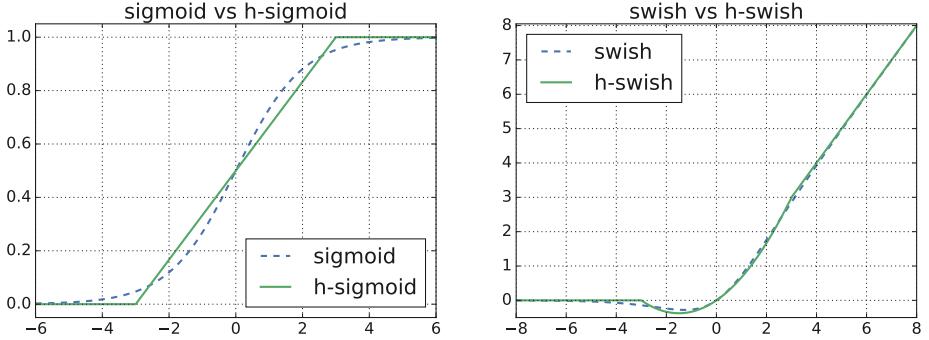
作者发现,
- 近似版本的h-swish能起到跟swish十分接近的作用
- h-swish无论在软件还是硬件层面都非常容易实现,而且解决了量化网络时sigmoid的近似实现带来的数值精度损失问题
模型结构
左图为large版本,右图为small版本——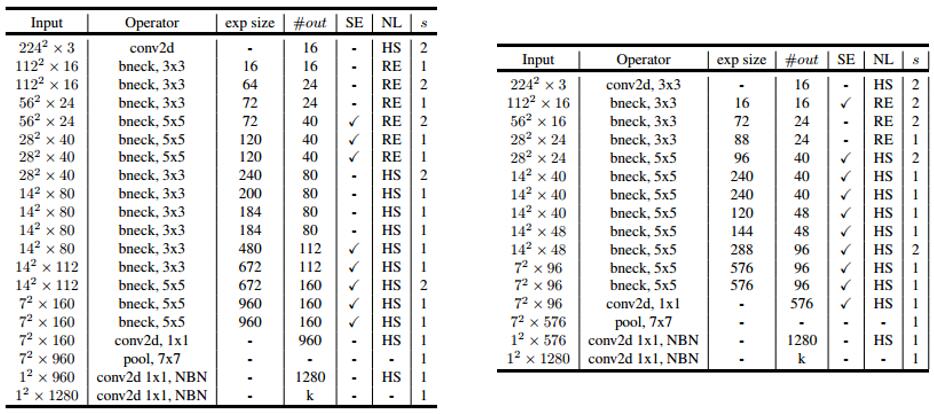
- 是否使用SE是platform-aware NAS权衡速度和精度之后做出的选择
- 由于h-swish的速度比relu慢,而浅层的特征图比较大,所以网络的浅层更倾向于更快的relu,只有在深层使用h-swish;不过第一层卷积的通道数比较少,再加上这里h-swish替代relu有比较好的效果,所以v3还是倾向于第一层卷积依旧使用h-swish
- 尽管3x3卷积已经成为手工设计网络主流,但似乎5x5卷积也有用武之地
FD-MobileNet
论文:《FD-MobileNet: Improved MobileNet with a Fast Downsampling Strategy(2018)》
Fast-Downsample MobileNet是MobileNet-v1的一个变种,采用快速下采样策略(提前下采样)来减小特征图尺寸,并增大网络宽度提高模型的特征提取能力,FD-MobileNet1.0和MobileNet0.5的比较——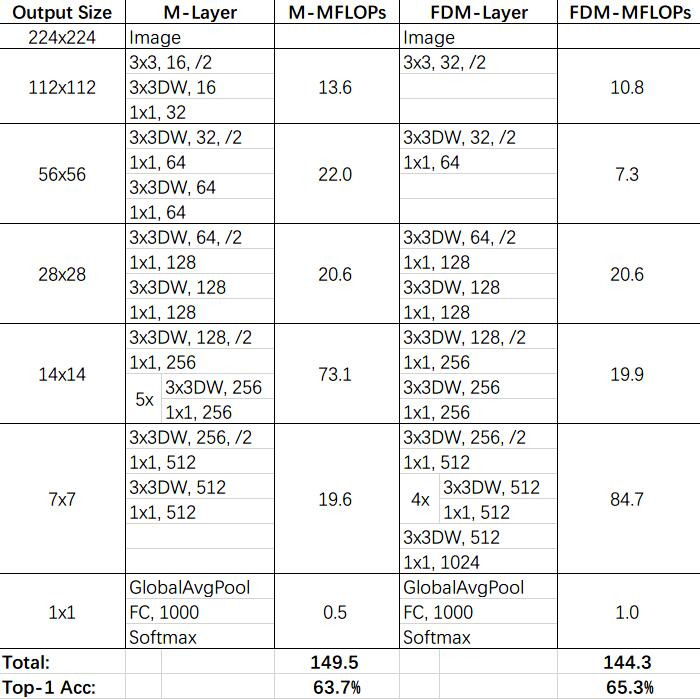
ImageNet上的实验结果
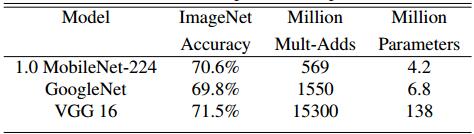
MobileNet v1
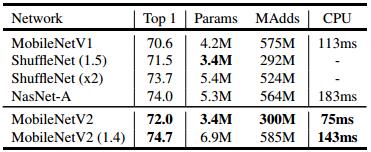
MobileNet v2
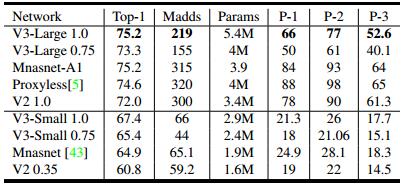
MobileNet v3
FD-MobileNet