MXNet上的重训练量化
本月初随手写了个简单的pip包,用来计算mxnet-gluon模型的参数数量和运算开销,从《模型参数与运算量 - 结果 | Hey~YaHei!》可以看到我们常用的CNN网络的大小和运算开销都是参差不齐的——比如常用的MobileNetv1虽然比ResNet50v1少了约6%的精度,但参数数量和运算量上看,ResNet50v1竟然是MobileNetv1的七倍左右!
而从《MobieleNets v1模型解析 | Hey~YaHei!》可以看到,与ResNet不同的是,MobileNets采用的是一种非常紧凑、高效的卷积计算。除了这种方式,还有许多模型压缩的技巧,比如按《当前深度神经网络模型压缩和加速都有哪些方法? - 机器之心》,可以把模型压缩分为参数修剪和共享、低秩因子分解、转移/紧凑卷积滤波器、知识蒸馏四个大类。
目前应用的比较多的,应该是属于参数修剪和共享类的裁剪和量化技术。模型压缩的水还很深,我只是这一两个月才开始入的门,不敢瞎扯。本文接下来只简单讨论一下量化技术。
量化
参考:《超全总结:神经网络加速之量化模型 | PaperWeekly》
简单的说,量化就是降低模型运算的精度,比如把32位的浮点运算变为8位的定点运算(甚至在二值网络或三值网络中乘法运算还变成了简单的加减运算),从而达到大幅度的压缩和加速模型。
常见的线性量化过程可以用以下数学表达式来表示:
$$r = Round(S(q - Z))$$
其中,
$q$ 是float32的原始值,
$Z$ 是float32的偏移量,
$S$ 是float32的缩放因子,
$Round(\cdot)$ 是四舍五入近似取整的数学函数,
$r$ 是量化后的一个整数值
$S$ 和 $Z$ 是量化的两个参数,如何找到合适的 $S$ 和 $Z$ 正是大家研究量化技术的最终目标。
或者可以换一个角度看,量化研究的是表示范围与精确度的权衡。
零点位置:对称量化和非对称量化
参考:Algorithms - Quantization | Distiller
$Z$ 参数的选择可以分为两类——对称和非对称。
对称量化
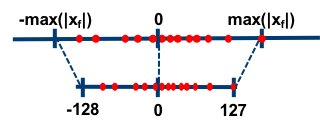
在对称量化中,$r$ 是用有符号的整型数值来表示的,此时 $Z=0$,且$r=0$ 正好是 $\frac{max(q)-min(q)}{2}$ 的量化结果。
比如简单地取,
$$S = \frac{2^{n-1} - 1}{max(|x|)}$$
$$Z = 0$$
其中,
$n$ 是用来表示该数值的位宽,
$x$ 是数据集的总体样本。
对称量化比较简单,不仅实现简单,而且由于$Z=0$运算也变得非常简单。
非对称量化
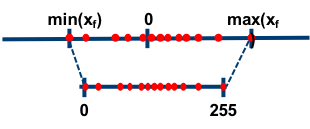
比如简单地取,
$$S = \frac{2^{n-1} - 1}{max(x)-min(x)}$$
$$Z = min(x)$$
非对称量化比较灵活,通常 $r$ 是用无符号的整型数值来表示,此时 $Z \neq 0$。
线性量化和截断量化【占坑】
还没看DoReFa和PACT的论文……
逐层量化和逐通道量化
逐层量化在整一层上使用同一对量化参数;
逐通道量化则是对每一个通道使用单独的量化参数;
后文中的重训练量化实现采用的是逐层量化
训练后量化和重训练量化
训练后量化
- 最简单的方式是直接利用最大最小值,比如量化权重时直接计算每一层里的权重的最大最小值然后代入上述的式子中计算S和Z,计算比较简单,即使在实际应用当中在加载模型时计算量化参数也不会有很大开销;
- 更为复杂的则是采用聚类算法,而不是简单的确定S和Z,此时运算会变得比较复杂——相邻两个数值间的差距不再是固定的,需要通过查表的方式来实现;
- 由于输入和激活是动态的,不像静态的权重可以直接事先计算好S和Z,所以在训练后量化中经常会将为输入动态计算S和Z;
- 为了让模型计算更快,也有一些技巧可以静态量化输入和激活,比如Quantization - MXNet | github 允许模型通过平滑平均的方式为每一个输入和激活确定静态的S和Z;
除此之外,一些论文以及《Algorithms - Quantization | Distiller》指出——
- 量化位宽小于8时,模型精度会出现比较严重的下降;
- 对于ResNet等冗余网络,训练后量化已经可以取得不错的效果;但对于MobileNet等紧凑的网络,训练后量化会对精度造成比较大的伤害;
- 对第一层卷积、最后一层全连接层进行量化会对精度造成比较大的伤害……
重训练量化
参考:《Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference(2017)》
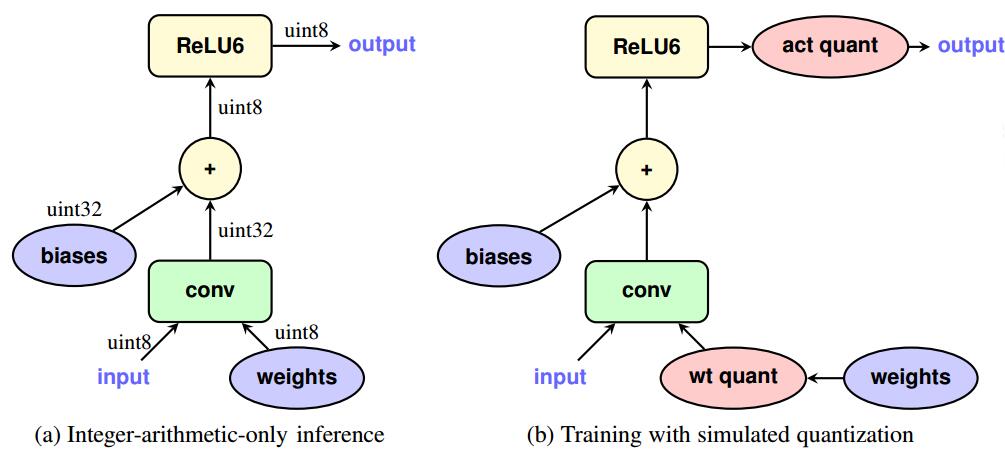
由于训练后量化会对MobileNet等紧凑网络的精度造成比较大的伤害,所以有人开始提出要进行重训练量化……
思路非常简单,把量化参数塞入网络当中,并在训练过程中模拟量化过程(缩放、偏移、截断、复原),用32位浮点数进行训练,最终将训练得到的量化参数固化到网络当中。
根据Tensorflow - Quantize模块的描述,Mobilenet-v1-224-1经过重训练后在ImageNet上的准确率从70.9%下降到69.7%(降幅1.2%)。
关于量化对准确率的影响,还有两件事情让人费解:
- 按照MXNet - Quantization给出的数据,仅仅使用校准而非重训练实现的静态量化,MobieleNet-1.0的准确率居然只下降了0.15%?!?!?!着实让人吃惊,不过要注意到它的单精度推断准确率也只有69.76%、而且测试数据集是他自己提供的一个
val_256_q90.rec的1.4G数据集——对,我试着探索了一番始终没查到这个数据集从哪来的,难道是MXNet自己做的?
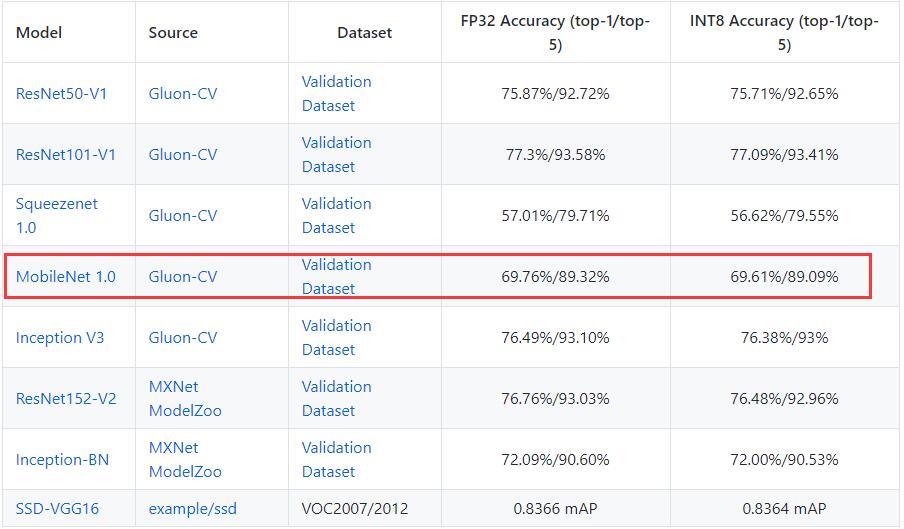
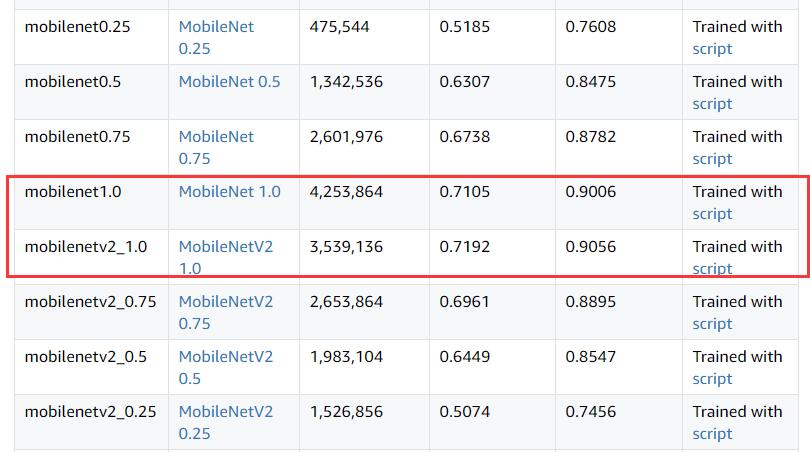
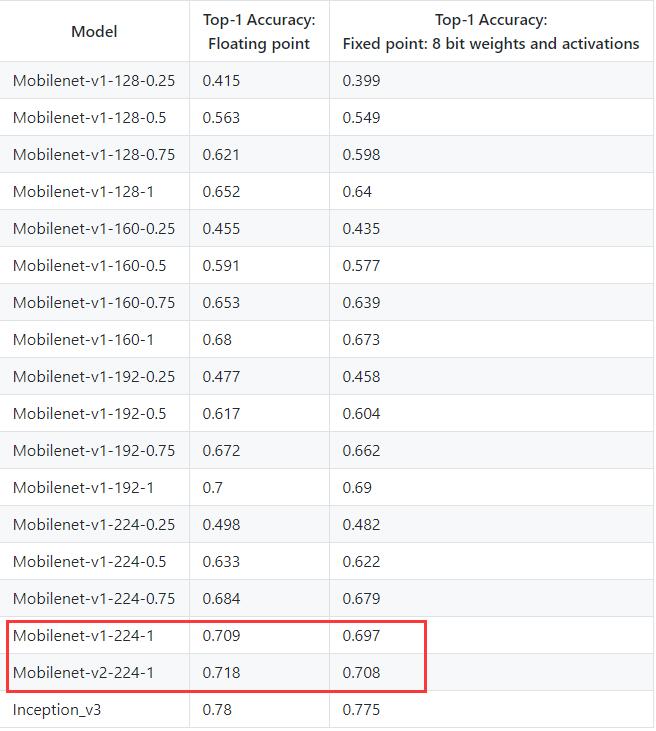
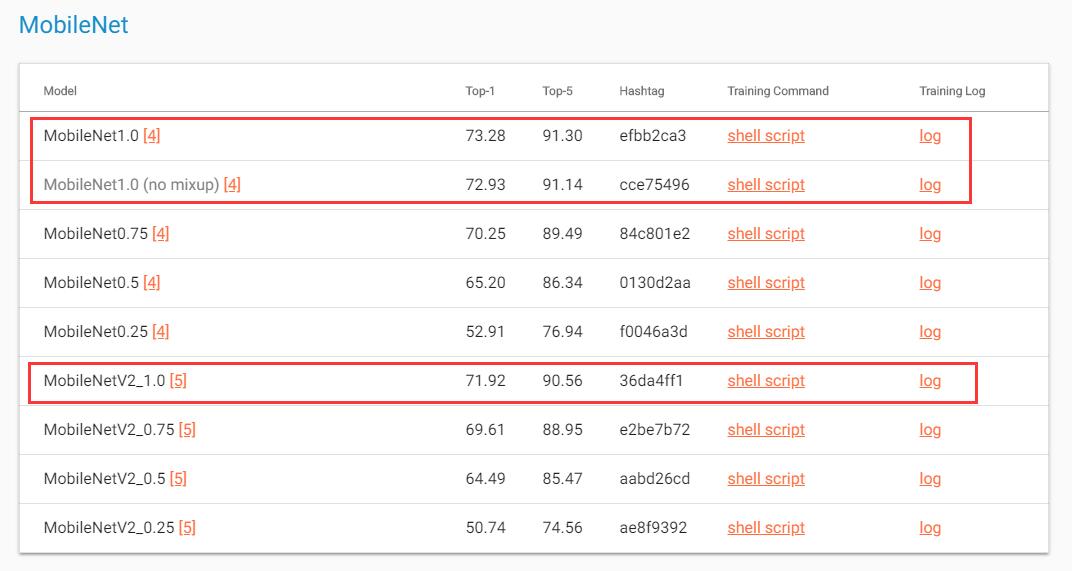
按照Gluon Model zoo的数据,MobileNetv1_224_1.0和MobileNetv2_224_1.0的准确率分别为71.05%和71.92%(文档没说测试集是哪,但一般应该用的是ILSVRC2012的验证集吧);另外按照Tensorflow - Quantize的数据,MobileNetv1_224_1.0和MobileNetv2_224_1.0的准确率分别为70.9%和71.8%(依旧没有指明测试集,应该也是ILSVRC2012验证集吧,不过这不是重点)——但到了Gluon CV的数据,MobileNetv1_224_1.0和MobileNetv2_224_1.0的准确率分别为73.28%和71.92%(其实他没指明输入图片尺寸,不过inception指明是299了,那其他网络应该也是默认的224吧)——v1竟然反而比v2多了一个百分点还多??(黑人问号……)
Gluon Model Zoo:
Tensorflow - Quantize:
Gluon CV:
重训练量化的MXNet实现
MXNet提供了简单的量化——Quantization - MXNet | github,不过可惜只支持简单的训练后量化。所以我决定参考Intel基于Pytorch实现的Distiller和谷歌的论文,实现一个简单的MXNet网络的重训练量化。
思路
项目已开源至github,这里只写一下大体的思路:
- 总体思路就是进行模拟量化,然后把量化参数作为可训练参数进行训练;
- 将relu都替换为relu6,因为我发现量化后如果还用relu,冗余网络影响不大,但对紧凑网络来说精度会骤减5%-6%,伤害很大;
- 改造gluon网络的思路跟我先前写的 OpSummary.MXNet | github 类似,往相关的Block塞Parameter、重写hybrid_forward对象函数、借助钩子(forward_hook和forward_pre_hook)来收集更新某些平滑参数;
- 通过解析参数名来匹配对应的参数(主要是在合并BN阶段);
- 利用MXNet提供的底层库函数(MXQuantizeSymbol)固化量化模型的结构,然后将对应的参数解算或映射到最终的参数名和数据类型(官方的底层库不支持静态量化,所幸这个改动不算麻烦,自己写了个脚本去把动态量化的max、min改为静态的数值就行);
- 训练前期输入和激活的量化用动态实现,同时用指数平滑平均(EMA)累积训练集上的最大最小值,当累积结果相对稳定(比如迭代一万次后)再改为静态量化对其他参数进行微调;
结果
量化前后
调试过程比较繁琐,所以为简单起见还没用ImageNet进行实验而使用了CIFAR100数据集(20分类,50000训练集,10000验证集),统一不使用数据增强来进行训练。分别训练出准确率分别为83.45%、84.20%、89.35%的MobileNet_1_0、MobileNet_1_0_ReLU6和ResNet50_v1作为baseline——
| Quantization | MobileNet_1_0_ReLU | MobileNet_1_0_ReLU6 | ResNet50_v1 |
|---|---|---|---|
| FP32 | 83.45% | 84.20% | 89.35% |
| UINT8_ONLINE | 76.61% | 77.66% | 89.11% |
| UINT8_OFFLINE_CALIB | 72.10% | 77.44% | 88.96% |
| UINT8_OFFLINE_RETRAIN | 80.72% | 83.03% | / |
| UINT8_OFFLINE_FAKEBN | 80.52% | 83.00% | / |
其中,
FP32 为单精度浮点下的模型;
UINT8_ONLINE 为8位非对称量化、动态量化激活的模型;
UINT8_OFFLINE_CALIB 为8位非对称量化、静态量化激活(在整个训练集上前向传播一次后用EMA校准最大最小值)的模型;
UINT8_OFFLINE_RETRAIN 为8位非对称量化、重训练(不合并BN层)的模型;
UINT8_OFFLINE_FAKEBN 为8位非对称量化、重训练(伪BN操作)的模型;
由于即使不重训练,ResNet精度也没有很明显的下降,所以调试过程中没有尝试对ResNet做重训练。
可以看到,即使没有重训练,量化后的Resnet50_v1也只有少量的精度下降;
但MobileNet_1_0精度下降非常明显,静态量化激活甚至会导致精度下降11%左右,不过经过重训练后静态量化激活的模型精度只下降了3.5%左右(其实依旧很多)……后来发现这是激活函数的缘故,把ReLU都替换成ReLU6之后,重训练静态量化的模型精度仅仅下降1.2%!
关于RELU6可以参考:Why the 6 in relu6? | stackoverflow,简单来说,ReLU6可以将定点数的整数部分限制在6以内,防止量化误差在传播过程中过分扩大。
伪·批归一化
不过吧,细心的你可能会想起来为了加快推断速度,往往会将BN层融到卷积、全连接等线性层中去(参考《MobileNet-SSD网络解析 - BN层合并 | Hey~YaHei!》)。现在BN层和卷积层之间隔着一个非线性的量化(因为有截断、取整、取最值的过程),这可怎么办?既然量化后不方便合并BN层,那在量化前(重训练前),提前把BN层融合掉好了,这就是论文《Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference(2017)》提到的伪BatchNorm操作,把BN层的参数都丢给卷积层,训练过程中卷积层既要做伪归一化,又要做伪量化!
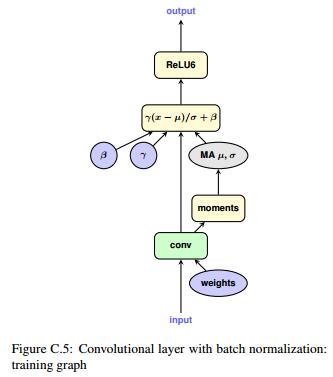
当然,这是有额外代价的,训练的前向传播过程中,需要做两次卷积运算——
- 用原始权重卷积,卷积输出用于更新伪BatchNorm的平均值、标准差,这次卷积运算不需要反向传播;
- 另外一次用量化过的权重卷积,卷积输出的结果作为下一层的输入,这一次的卷积运算需要反向传播
这样一来,训练速度大概会下降30%-40%左右(实测);
另外,不引入伪·批归一化的情况下,重训练收敛非常快!几乎算是迭代几百次(哦,我用的是Adam)就接近收敛,引入后精度下降特别厉害(起初甚至以为我程序有问题,然后反复验证我伪BN的输出结果),需要训一段时间才能得到最后的结果:
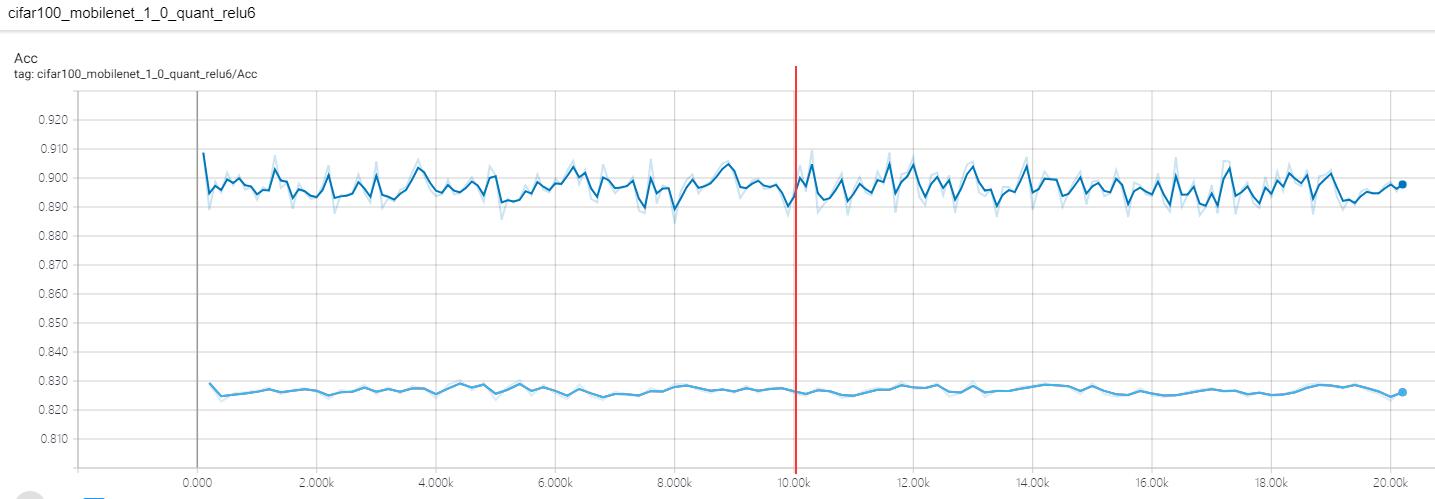
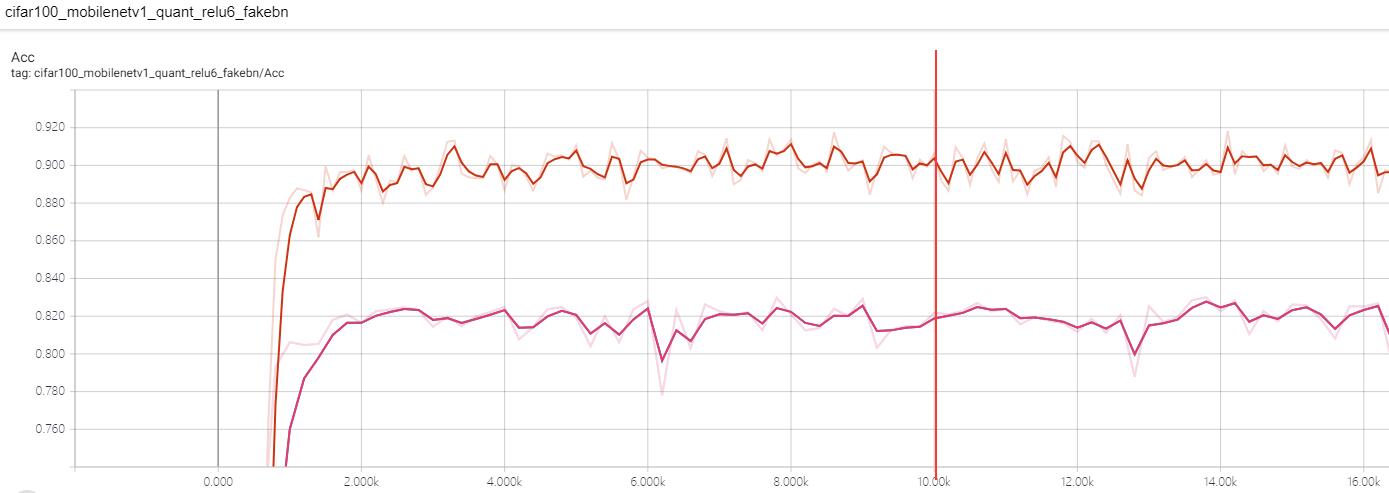
图(上):不合并BN的学习曲线(前一万次迭代采用动态量化(lr=1e-5),之后转为静态量化做微调(lr=1e-5))
图(下):合并BN后的学习曲线(前一万次迭代采用动态量化(lr=1e-5),之后转为静态量化做微调(lr=1e-6))
推荐阅读
- Tensorflow - Quantize:Tensorflow的重训练量化模块
- Tensorflow - Quantization:Tensorflow的量化OP
- MXNet - Quantization:MXNet的训练后量化模块
- Neural Network Distiller:Intel的开源模型压缩库(基于Pytorch)
- 《Quantizing deep convolutional networks for efficient inference: A whitepaper》
谷歌Tensorflow官方发布的量化白皮书,译文可参考 CSDN上Colie-Li的翻译 - 《当前深度神经网络模型压缩和加速都有哪些方法? | PaperWeekly, 小一一
- 《让机器“删繁就简”:深度神经网络加速与压缩 | 深度学习大讲堂, 程健》
- 《超全总结:神经网络加速之量化模型 | PaperWeekly, 郝泽宇》
- 《模型压缩开源库整理 | CSDN, 库页》
下一步
- 编了freeze的代码,输出来的静态图结构看起来也符合预期,但目前还没实际加载运行过
(因为不巧,MXNet对量化的支持还不够好,官方的Quantization - MXNet分为普通CPU推断和Xeon系列的CPU推断,前者竟然不支持带group的卷积,实验室的电脑又正好都是i系列的,十分头疼= =等开了学我再想办法找台Intel Xeon处理器的电脑测试一下)好像不是处理器的缘故,mkldnn应该是支持所有的intel处理器的吧,现在关键是Symbol居然没有get_backend_symbol方法,我装的应该是最新版本才对啊; - 除了验证freeze结果之外,还需要测一下量化后的模型推断速度有多大提升;
- 尝试逐通道量化;
- 训完的模型目前只能在台式机跑跑,想再看看有没有可能在Tengine或ncnn上跑跑我的量化模型;
- 看起来量化的效果还不错,但我比较好奇量化后的模型跨数据集时会不会出现严重的精度下降,可以做个实验比较一下~
- 目前只对分类网络进行量化,想试一下对检测网络MobileNet-SSD和人脸识别网络MobileFaceNet网络的量化结果;
- 继续看看DoReFa和PACT的量化方式;
代码还比较粗糙,等着开了学再进一步完善吧!