基于MobileNet-SSD的目标检测Demo(一)
上一篇文章《训练MobileNet-SSD | Hey~YaHei!》介绍了如何训练自己的MobileNet-SSD模型并部署在Tengine平台上。
本文将继续尝试根据实际情况删减多余类别进行训练,并用Depthwise Convolution进一步替换Standard Convolution。
削减类别
VOC数据集包含二十个类别的物体,分别是——aeroplane, bicycle, bird, boat, bottle, bus, car, cat, chair, cow, diningtable, dog, horse, motorbike, person, pottedplant, sheep, foa, train, tvmonitor,有时候我们想用VOC数据集训练,但并不需要这么多类别,而caffe-ssd提供的数据处理工具create_list.sh和create_data.sh默认是处理所有的20个分类的。如果我们不想重写这些数据处理工具,可以从根源入手,也就是直接修改数据集里的标注信息,把多余分类的信息删去。
处理数据集
首先观察一下VOC数据集的结构——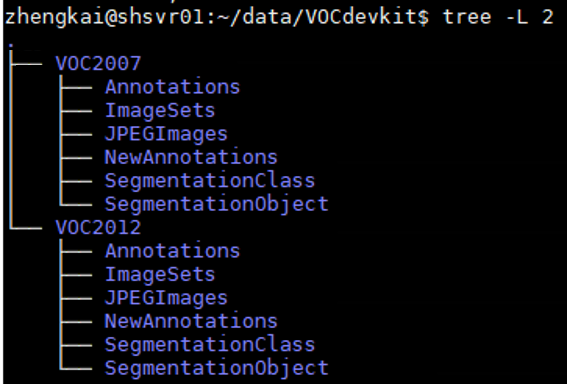
- Annotations:存放图片的标注信息,每张图片对应一个xml文件
- ImageSets:存放图片的分类列表,包含三个子目录:
- Layout:存放与人体部位有关的图片列表文件
- Main:存放物体分类中每一个分类的图片列表文件
- Segmentation:存放与图像分别有关的图片列表文件
- JPEGImages:存放所有的图片
NewAnnotations:忽略吧……是我自己生成的目录- SegmentationClass:存放类别分割任务的蒙版文件
- SegmentationObject:存放实体分割任务的蒙版文件
JPEGImages目录下每张图片都包含一到多个物体,这些物体的位置、类别信息都记录再Annotations目录下的同名xml文件中,文件内容类似:
<annotation>
<folder>VOC2007</folder>
<filename>008973.jpg</filename>
<source>
<database>The VOC2007 Database</database>
<annotation>PASCAL VOC2007</annotation>
<image>flickr</image>
<flickrid>335707085</flickrid>
</source>
<owner>
<flickrid>kjmurray</flickrid>
<name>Katherine Murray</name>
</owner>
<size>
<width>500</width>
<height>333</height>
<depth>3</depth>
</size>
<segmented>1</segmented>
<object>
<name>cow</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>271</xmin>
<ymin>43</ymin>
<xmax>444</xmax>
<ymax>279</ymax>
</bndbox>
</object>
</annotation>
而caffe-ssd的数据处理工具正是根据这些xml文件提供的标记进行处理的,所以说,我们可以通过遍历xml文件,判断object的类别,如果是我们不需要的,则把对应的object标签删去来达到削减类别的目的,除此之外还要处理对应的图片路径列表和图片大小列表,删除多余的项。
根据这一思路,可以写一个简单的py脚本来实现:
#!/usr/bin/python
#-*- coidng: utf-8 -*-
import xml.etree.ElementTree as ET
import os
VOC_ROOT = "/home/zhengkai/data/VOCdevkit/"
CLASS2KEEP = ('background',
'aeroplane', 'bird',
'bottle', 'bus', 'car', 'chair',
'dog', 'bicycle', 'motorbike',
'boat', 'sofa')
def process_xml(src_path, dst_path):
"""
解析并处理xml文件——
解析源文件,删除无关object标签,
如果存在有效object,则写入到目标文件,并返回True;
否则,直接返回False。
"""
tree = ET.parse(src_path)
root = tree.getroot()
no_objs = True
for obj in root.findall("object"):
cls = obj.find("name").text
if cls not in CLASS2KEEP:
root.remove(obj)
else:
no_objs = False
if not no_objs:
tree.write(dst_path)
return True
else:
return False
if __name__ == "__main__":
# 记录有效的xml文件名
valid_lst = []
# 处理xml文件,新的xml文件写入到NewAnnotations目录下
for dataset in ["VOC2007/", "VOC2012/"]:
raw_anno_dir = VOC_ROOT + dataset + "Annotations/"
dst_anno_dir = VOC_ROOT + dataset + "NewAnnotations/"
if not os.path.exists(dst_anno_dir):
print("Create a new dir: " + dst_anno_dir)
os.mkdir(dst_anno_dir)
for xml_filename in os.listdir(raw_anno_dir):
if process_xml(raw_anno_dir + xml_filename, dst_anno_dir + xml_filename):
valid_lst.append(xml_filename.split(".")[0])
# 处理图片路径列表txt文件,根据valid_lst筛选有效的图片路径
for filename in ["test.txt", "trainval.txt"]:
with open("new_" + filename, "w") as nf:
with open(filename, "r") as of:
for line in of.readlines():
if line.split("/")[-1].split(".")[0] in valid_lst:
nf.write(line.replace("Annotations", "NewAnnotations"))
# 处理图片大小列表txt文件,根据valid_lst筛选有效的图片大小
with open("new_test_name_size.txt", "w") as nf:
with open("test_name_size.txt", "r") as of:
for line in of.readlines():
if line.split(" ")[0] in valid_lst:
nf.write(line.replace("Annotations", "NewAnnotations"))
生成lmdb文件
修改caffe-ssd数据处理工具中的标签映射文件labelmap_voc.prototxt,该文件由若干个类似下边的item组成:
item {
name: "none_of_the_above"
label: 0
display_name: "background"
}
- name:物体类别在xml文件中出现的名称
- label:标签对应的数值(为方便处理,建议序号从0递增)
- display_name:该类别最后要展示出来的名称
删除映射文件中多余类别对应的item,然后按顺序重新为各个类别编号(修改label项);
修改create_list.sh脚本,将第29行的Annotations改为NewAnnotations——
[27] label_file=$bash_dir/$dataset"_label.txt"
[28] cp $dataset_file $label_file
[29] sed -i "s/^/$name\/NewAnnotations\//g" $label_file
[30] sed -i "s/$/.xml/g" $label_file
然后跟上一篇文章一样,依次执行脚本create_list.sh和create_data.sh即可。
训练和部署
训练和部署过程与 《训练MobileNet-SSD/开始训练MobileNet-SSD/训练(部署) | Hey~YaHei!》 基本相同;
微小的区别在于,
- 生成模型文件时
./gen_model.sh 21中21要换成实际的类别数量(含背景background); - 要使用新的标签映射文件
labelmap.prototxt; - 应用程序中标签要对应修改
如《RK3399上Tengine平台搭建/目标检测网络MobileNet-SSD | Hey~YaHei!》最后列出的代码中,post_process_ssd函数里的class_names数组常量要对应修改(索引号与labelmap.prototxt文件里的label标签一一对应)。
Depthwise Convolution和Standard Convolution(Group)的比较
观察chuanqi305的 MobileNet-SSD模型文件deploy.prototxt 可以发现,其中的Depthwise Convolution都是使用特殊的caffe原生卷积层(group参数与num_output参数相等)来实现的。
查阅caffe官方文档,
group (g) [default 1]: If g > 1, we restrict the connectivity of each filter to a subset of the input. Specifically, the input and output channels are separated into g groups, and the ith output group channels will be only connected to the ith input group channels.
可以知道,group参数强制输入通道和输出通道分为若干组,一组输入通道卷积运算得到组序相同的输出通道,所以使 group == num_output 确实可以得到与Depthwise Convolution相同的结果。但是,“分组”?从字面的意思上看,不免让人怀疑,这个group是不是通过简单的循环实现的,如果真是如此,不同的group还会并行的计算吗?我们不妨做个简单的实验——
我在github上找到第三方实现的 caffe - Depthwise Convolution层,根据其README的说明将其放到caffe源码下重新编译caffe-ssd得到专门实现的DepthwiseConvolution。
在单卡GTX1080Ti、Intel E5-2683环境下测试结果如下(分别重复运行100次,单位:秒/百次):
| caffe-mode | Standard Convolution(Group) | Depthwise Convolution |
|---|---|---|
| cpu-only | 26.13568 | 23.40233 |
| gpu | 6.93938 | 0.53499 |
| gpu-cudnn | 6.86799 | 0.53779 |
很显然,在cpu-only模式下,两者没有太大区别;在gpu模式下(无论是caffe自身的加速库还是cudnn加速库),专门实现的DepthwiseConvolution都要快10倍左右!
除此之外,Depthwise Convolution Layer | github的README也给出了一些测试数据。
那Tengine有专门实现的DepthwiseConvolution层吗?
从官方的文档上看,确实没有专门的DepthwiseConvolution层,如果试着在模型文件里使用DepthwiseConvolution也会看到报错。不过!在源码 executor/operator/arm64/conv/conv_2d_dw.cpp | github, Tengine可以看到有一个 isDepthwiseSupported 函数——
static bool isDepthwiseSupported(const ConvParam * param, const TShape& input_shape)
{
int input_c=input_shape.GetC();
int group=param->group;
int kernel_h=param->kernel_h;
int kernel_w=param->kernel_w;
int stride_h=param->stride_h;
int stride_w=param->stride_w;
int dilation_h=param->dilation_h;
int dilation_w=param->dilation_w;
int pad_h0=param->pads[0];
int pad_w0=param->pads[1];
int pad_h1=param->pads[2];
int pad_w1=param->pads[3];
if(group == 1 || input_c != group || kernel_h != 3 || kernel_w != 3 ||
pad_h0 != 1 || pad_w0 !=1 || pad_h0 != pad_h1 || pad_w0 != pad_w1 ||
dilation_h != 1 || dilation_w != 1 || stride_w != stride_h)
{
return false;
}
return true;
}
也就是说,Tengine会自行判断Convolution层是否属于DepthwiseConvolution并相应作出优化,对应的汇编实现为 executor/operator/arm64/conv/dw_k3s1p1.S | github, Tengine。
进一步替换Depthwise Convolution
从《MobileNet-SSD网络解析 | Hey~YaHei!》一文中可以看到,chuanqi305在设计MobileNet-SSD时还是保守地在Conv14_1到Conv17_2使用Standard Convolution,我们不妨进一步把这一部分也替换为深度向分解的卷积,替换的方式也很简单,举个例子:
对于某个传统的Convolution层
layer {
name: "conv14_2"
type: "Convolution"
bottom: "conv14_1"
top: "conv14_2"
param {
lr_mult: 1.0
decay_mult: 1.0
}
param {
lr_mult: 2.0
decay_mult: 0.0
}
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
stride: 2
weight_filler {
type: "msra"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "conv14_2/relu"
type: "ReLU"
bottom: "conv14_2"
top: "conv14_2"
}
修改为
layer {
name: "conv14_2_new/dw"
type: "DepthwiseConvolution"
bottom: "conv14_1_new"
top: "conv14_2_new/dw"
param {
lr_mult: 0.1
decay_mult: 0.1
}
convolution_param {
num_output: 256
bias_term: false
pad: 1
kernel_size: 3
stride: 2
group: 256
engine: CAFFE
weight_filler {
type: "msra"
}
}
}
layer {
name: "conv14_2_new/dw/relu"
type: "ReLU"
bottom: "conv14_2_new/dw"
top: "conv14_2_new/dw"
}
layer {
name: "conv14_2_new"
type: "Convolution"
bottom: "conv14_2_new/dw"
top: "conv14_2_new"
param {
lr_mult: 0.1
decay_mult: 0.1
}
convolution_param {
num_output: 512
bias_term: false
kernel_size: 1
weight_filler {
type: "msra"
}
}
}
layer {
name: "conv14_2_new/relu"
type: "ReLU"
bottom: "conv14_2_new"
top: "conv14_2_new"
}
要注意几点,
- 修改后的层要给个新的名字,避免初始化权重的时候从预训练好的模型误导入权重;
- 训练模型
train.prototxt和测试模型test.prototxt可别忘了加上BN层; - 部署在Tengine上的时候要记得把type从
DepthwiseConvolution替换为Convolution。
……其他层也做类似的修改即可。
替换前后比较——
| VOC2007-test | MobileNet-SSD | MobileNet-SSDLite |
|---|---|---|
| mAP | 0.727 | 0.718 |
| FPS(1080Ti) | 258 | 278 |
| caffemodel | 23MB | 16MB |
本文介绍了如何削减VOC数据集上多余类别进行训练,并且尝试用深度向分解的卷积层进一步替换传统的卷积层,同时比较了专门优化加速的DepthwiseConvolution和Convolution(Group)在效率上的差别。
下一篇文章《基于MobileNet-SSD的目标检测Demo(二)》将介绍如何把目标检测和视频解码与显示分别放到两个线程上,来提高目标检测demo的流畅性。