基于MobileNet-SSD的目标检测Demo(二)
上一篇文章《基于MobileNet-SSD的目标检测Demo(一)》介绍了如何在VOC数据集的基础上削减分类训练出自己的分类器,并且尝试着进一步把SSD改为SSDLite。但作为一个Demo,在RK3399上MobileNet-SSD每秒钟只能检测6-7帧,如果每次检测后再把视频内容展现出来,那么展示的视频也只有6-7帧,这样的展示效果似乎不太好。在本篇文章中,我们将尝试把视频的获取与展示和检测任务分离开来,分别放在两个不同的线程上工作,同时将不同的线程绑定到不同的cpu核上,使得两者的工作不会冲突。
进程和线程
进程和线程是操作系统中的两个重要概念。
背景
考虑在51单片机或是STM32上开发程序,通常这些程序都是串行结构。打个比方,
- 写个数码管的动态驱动,让四个个数码管持续显示数值
1217while(1){ segmentShow(1217); } - 用一个超声波模块进行测距,并且用数码管显示结果
while(1){ ultrasonicTrig(); while(!ultrasonicDataValid()); segmentShow(ultrasonicGetDatum()); } - 超声波数量少还没关系,数码管还是能正常驱动,如果多来几个呢?(简化一下,数码管只显示求和的结果)
CPU大部分时间都用去等超声波信号了呀,数码管根本就不能驱动起来,那换种方式——while(1){ for(i=0; i<100; i++){ ultrasonicTrig(i); while(!ultrasonicDataValid(i)); } segmentShow(sum(ultrasonicgetDatum())); }
这样一来,如果超声波数据无效就继续驱动数码管,不会让CPU空等。i=0; segment=0; sum=0; ultrasonicTrig(i); while(1){ if(ultrasonicDataValid(i)){ sum+=ultrasonicGetData(i); ultrasonicTrig(++i); } if(i>=99){ segment=sum; i=sum=0; } segmentShow(segment); } - 那如果不是简单的求和运算呢?
万一i=0; segment=0; ultras[100]; ultrasonicTrig(i); while(1){ if(ultrasonicDataValid(i)){ ultras[i]=ultrasonicGetData(i); ultrasonicTrig(++i); } if(i>=99){ segment=process(ultras); // 变成了其他复杂的运算 i=0; } segmentShow(segment); }process函数运算过程很复杂,占用了很多CPU的时间,导致数码管不能及时刷新,那数码管依旧驱动不起来。当然,你可以去推算process运算的复杂程度,人为地去拆解运算,变成process[0]、process[1]、……、process[n]最后再由combine把中间结果整合起来(注意这里要保证每个操作都足够小,不会占用太多运算时间)。
看起来确实可行,但是手工拆解运算,这也太恶心了吧,而且这一点都不优雅,万一我程序开发着开发着,这个运算过程发生改变了怎么办?重新拆解运算?那不得炸毛?!i=0; i_process=0; segment=0; ultras[100]; tmp[10]; ultrasonicTrig(i); while(1){ if(ultrasonicDataValid(i)){ ultras[i]=ultrasonicGetData(i); ultrasonicTrig(++i); } if(i>=99){ tmp[i_process]=process[i_process](ultras); if(i_process==9){ segment=combine(tmp); i_process=0; }else{ i_process++; } i=0; } segmentShow(segment); } - 那换个思路,我们让两个任务分时进行吧,每个任务轮流运算10ms,超时就带上你的中间结果滚蛋
这样虽然增加了额外的开销(任务的调度),但形成了一个通用化的任务调度功能,无论具体任务怎么改变都能够适用,减少CPU闲置的机会,可以更好的压榨CPU// 设置定时器,每10ms中产生一次中断 timer_handler(){ // 中断处理 save_metadata(); // 触发中断后保存数据 change_task(); // 切换到另一个任务 load_metadata(); // 取出新换入任务的中间数据 task_run(); // 继续任务 } // ……省略任务定义
实际应用当中,我们经常都能碰见这种多任务的情况,人为地分配任务给处理器需要大量的推算和分解,费时费力还不易调整。在这里,我们形成了一个简单的通用的任务调度功能,其实这也是现代操作系统的基本功能之一,对操作系统而言,这些任务就是一个个的“进程”,中间数据被称为“进程上下文”,而操作系统有一个专门的模块负责“进程调度”的工作,这里举例的固定时间片是一种最简单的调度方式。
进程
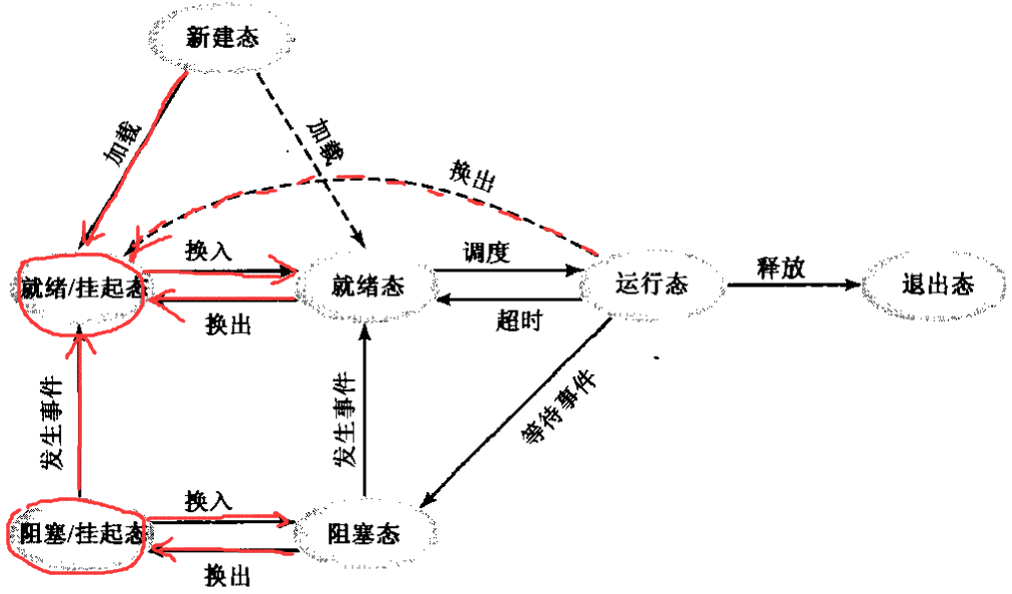
这是一张进程状态转换图,
- 新建一个进程时处于“新建态”,至于加载到“就绪态”还是“就绪/挂起态”就取决于操作系统翻不翻你牌子;
- “就绪态”指的是进程已经就绪的状态,比如进程执行所需要的资源(比如键盘、鼠标、显卡等外设)可用,并且已经被操作系统翻牌,在等待执行的队伍里排着队;
- “阻塞态”指的是进程未就绪,比如执行的所需资源还未到位,进程本身处于等待的状态;
- “就绪态”和“阻塞态”还分别有对应的“就绪/挂起态”和“阻塞/挂起态”,这是进程本身处于就绪或未就绪的状态,但操作系统还没有翻他们牌子;
- “运行态”和“退出态”不难理解,就是进程运行中的状态,以及进程完全运行结束而将退出的状态
进程上下文保存在一个特殊的称为进程控制块(PCB)的结构里,其中包含
- 进程标识信息(各种标识符)
- 进程状态信息(寄存器、栈指针等)
- 进程控制信息(调度和状态的相关信息,比如进程状态、优先级、事件等)
常见的用户进程创建有两种,
- 用户运行一个程序,这个程序会放到一个进程上
比如直接运行一个编译好的c程序,或是一个python程序; - 由现有进程派生
比如在c程序中调用fork函数来派生出一个新的进程——#include <stdio.h> int main (){ int pid, ppid; pid = fork (); // fork函数将派生出一个相同的进程,返回新进程的id(对于原始进程返回0) printf ("%d first output from both processes\n", pid); sleep (20); if (pid > 0){ printf ("%d %s", pid, "This is the child's pid, output by the parent process\n"); }else if (pid ==0){ printf ("%d %s", pid, "is printed inside the child process if the fork succeeds \n"); pid = getpid(); // getpid函数可以获取当前进程的id printf ("%d %s", pid, "is the child pid printed by the child, obtained by getpid()\n"); }else printf ("fork failed\n"); return (0); }
进程间的通信通常由信号量、中断和共享空间实现,简单地说,
- 信号量,事实上就是一个整型变量。操作系统负责维护一个信号量池,进程可以在该池注册带有名称的信号量,多个进程间可以对同一个信号量进行加法或减法操作(通常称为PV操作,该操作由操作系统管理,不会读写冲突),但减法的结果不能小于0,否则进程就会阻塞挂起,等待有足够的信号量可以减去。信号量有点像资源的指示标志,进程占用资源的时候作减法,释放资源的时候做加法。
- 中断,是Linux提供的一套机制,事实上
kill指令就是对目标进程发送一个特定的中断信号,进程接收到中断之后会跳转到指定的中断处理函数进行处理(当然进程也可以设置忽略某一些信号)。在Linux中可以通过指令kill -l查看可用信号,如下:
不同的信号有不同的含义,其中10号的# kill -l 1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP 6) SIGABRT 7) SIGBUS 8) SIGFPE 9) SIGKILL 10) SIGUSR1 11) SIGSEGV 12) SIGUSR2 13) SIGPIPE 14) SIGALRM 15) SIGTERM 16) SIGSTKFLT 17) SIGCHLD 18) SIGCONT 19) SIGSTOP 20) SIGTSTP 21) SIGTTIN 22) SIGTTOU 23) SIGURG 24) SIGXCPU 25) SIGXFSZ 26) SIGVTALRM 27) SIGPROF 28) SIGWINCH 29) SIGIO 30) SIGPWR 31) SIGSYS 34) SIGRTMIN 35) SIGRTMIN+1 36) SIGRTMIN+2 37) SIGRTMIN+3 38) SIGRTMIN+4 39) SIGRTMIN+5 40) SIGRTMIN+6 41) SIGRTMIN+7 42) SIGRTMIN+8 43) SIGRTMIN+9 44) SIGRTMIN+10 45) SIGRTMIN+11 46) SIGRTMIN+12 47) SIGRTMIN+13 48) SIGRTMIN+14 49) SIGRTMIN+15 50) SIGRTMAX-14 51) SIGRTMAX-13 52) SIGRTMAX-12 53) SIGRTMAX-11 54) SIGRTMAX-10 55) SIGRTMAX-9 56) SIGRTMAX-8 57) SIGRTMAX-7 58) SIGRTMAX-6 59) SIGRTMAX-5 60) SIGRTMAX-4 61) SIGRTMAX-3 62) SIGRTMAX-2 63) SIGRTMAX-1 64) SIGRTMAXSIGUSR1和12号的SIGUSR2是两个可以用户自定义的中断信号。 - 共享空间,类似进程内部的全局变量,由操作系统负责维护,跟信号量一样各个共享空间拥有自己的标识符,不同进程都可以访问相同的共享空间,但是要注意防止访问冲突(比如一个进程对空间写操作,同时又有另一个进程对空间进程读或写操作),这通常是通过信号量来实现的。并且在共享的过程要注意避免进程死锁(各个进程各自占有一部分但并不充足资源,导致进程同时陷入无休止的阻塞状态),有一些专门用于检测死锁和防止死锁的算法,此处不展开讨论。
具体的实现不展开讲,因为我们接下来要用到的是线程而不是进程。
如果你对进程间通信感兴趣,也可以参考我本科期间的一个课程作业,一个 简单的本地聊天程序 (具体使用方法参见chat.c里的注释)。
线程
在单一程序中,进程的粒度似乎还是太大了,如果把一个程序的大任务细分多个小任务,明明大家都是同一个目标,却要使用独立的上下文,上下文频繁地保存和加载,这样似乎不太方便。于是就产生了粒度更小的线程,一个进程可以拥有多个线程,这些线程共享一个上下文环境。
相比于进程,
- 创建一个线程的速度要快得多;
- 终止一个线程的速度也要快得多;
- 线程间的切换也比进程间切换快,因为不需要交换上下文;
- 线程的通信效率更高,因为线程可以直接通过共享全局变量来实现通信。
线程的通信方式比进程简单,这跟进程的“信号量+共享空间”的组合有些类似,
- 线程锁,类似进程通信中的信号量,但这个变量只有两种状态——“上锁”和“解锁”,用于保护共享的内存空间不会出现读写冲突;
- 全局变量,类似进程通信中的共享空间。
简单的实现方式——
#include <pthread.h>
pthread_mutex_t mutex; // 线程锁(用于保护shared_variable变量)
int shared_variable = 0; // 线程间共享的全局变量
void *thread_write(void *){
pthread_mutex_lock(&mutex); // 写入前上锁(如果mutex锁住,则阻塞等待)
shared_variable++;
pthread_mutex_unlock(&mutex); // 写入后解锁
}
void *thread_read(void *){
pthread_mutex_lock(&mutex); // 读取前上锁(如果mutex锁住,则阻塞等待)
printf("%d\n", shared_variable++);
pthread_mutex_unlock(&mutex); // 读取后解锁
}
int main(){
pthread_t id1, id2;
pthread_mutex_init(&mutex, NULL); // 初始化线程锁
pthread_create(&id1, NULL, thread_write, NULL); // 创建写线程
pthread_create(&id2, NULL, thread_read, NULL); // 创建读线程
pthread_join(id1, NULL); // 阻塞主线程,等待线程id1执行完毕
pthread_join(id2, NULL); // 阻塞主线程,等待线程id2执行完毕
pthread_mutex_destroy(&mutex); // 销毁线程锁
return 0;
}
pthread_create、pthread_join、pthread_mutex_init还可以传递其他参数,其他复杂的用法可以自行查阅资料。
处理器调度
在背景中我们提到了一种规定时间的调度方法,接下来我们也简单介绍其他一些处理器的调度策略。
假设有A-E五个进程集合,他们的启动时间和CPU占用总时间如下表所示——
| 进程 | 启动时间 | CPU占用总时间 |
|---|---|---|
| A | t=0 | 3 |
| B | t=2 | 6 |
| C | t=4 | 4 |
| D | t=6 | 5 |
| E | t=8 | 2 |
先来先服务策略(First Come First Served, FCFS)
非抢占策略,进程依次进入等待队列,先进入队列的先使用CPU,直到进程结束再从队列取出下一个进程。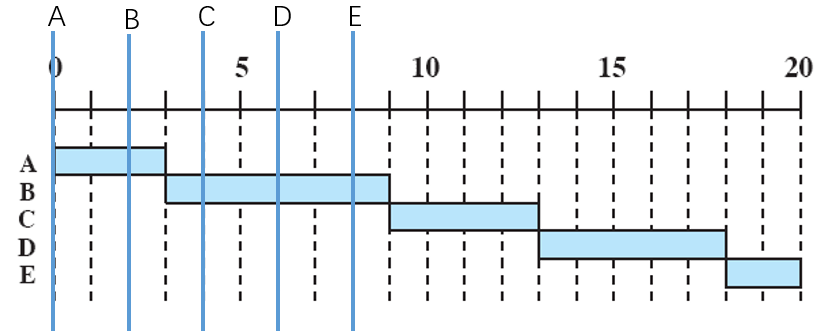
轮转策略(Round Robin, RR)
一种基于时钟的抢占策略,又称为时间片策略,设定一个时间片q,每次从进程等待队列中取出一个进程执行一个时间片,如果没执行完就放回等待队列的队尾,然后从队首取出下一个进程出来执行一个时间片。假设q=1,则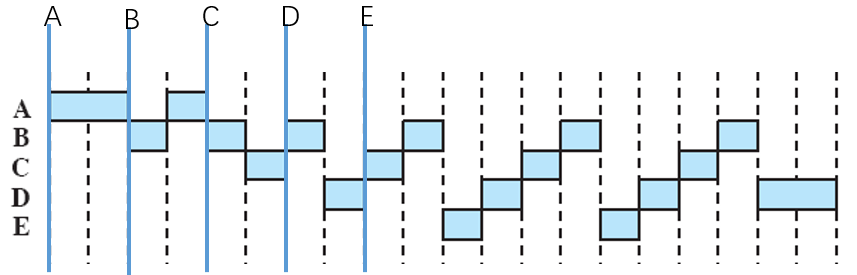
注意:这里假设如果同时发生“中断”和“新服务入队”,则先将新服务入队,再交换进程。
最短进程优先(Shortest Process Next, SPN)
一种基于预计处理时间的非抢占策略,每次从等待队列中取出预计处理时间最短的进程出来执行,直到进程结束再从进程取出下一个预计处理时间最短的进程。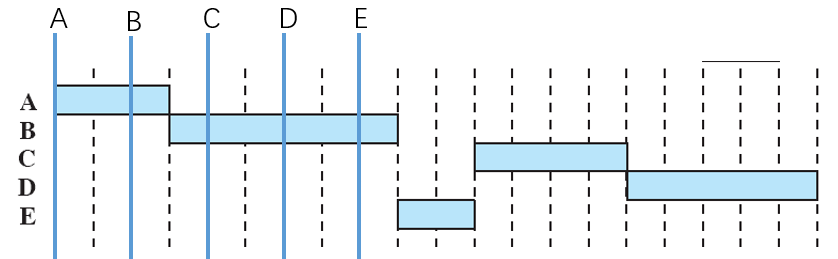
最短剩余时间(Shortest Remaining Time, SRT)
一种基于预计剩余处理时间的抢占策略,在SPN的基础上,当有新进程加入队列时总会估算各个进程的剩余时间,然后选择预计剩余处理时间最短的进程出来执行。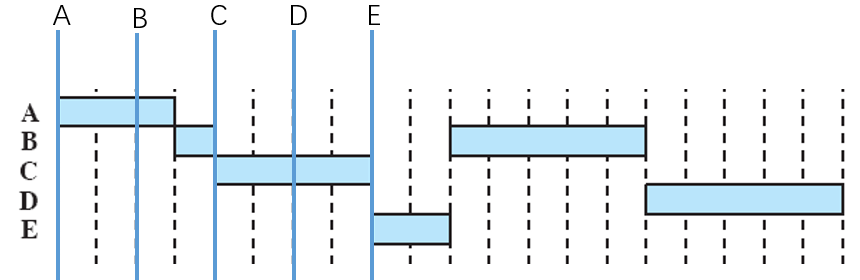
最高响应比优先(Highest Response Ratio Next, HRRN)
非抢占策略,定义一个响应比参数,$响应比=\frac{等待时间+预计处理时间}{预计处理时间}$,每次从等待队列中挑选响应比最高的进程出来执行,直到进程执行结束再从队列中取出下一个响应比最高的进程。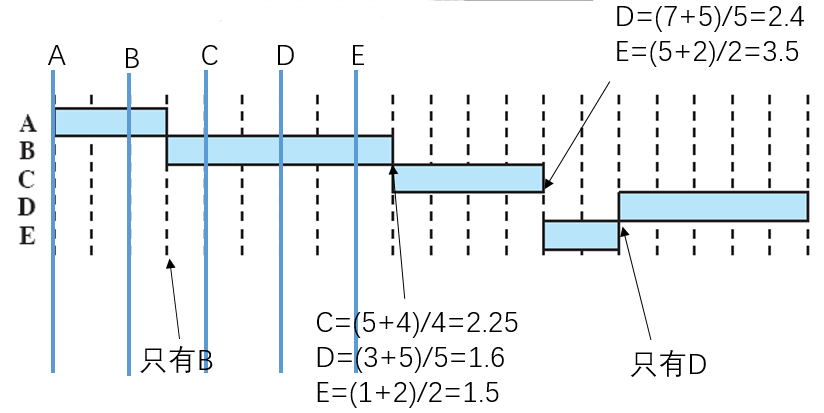
反馈调度
可以注意到FCFS、RR策略相对简单,不太能很好的利用CPU,而SPN、SRT、HRRN策略虽然不错,但依赖于处理时间和剩余处理时间的估计,而现实应用中这种时间估计往往是难以实现的。因此产生了反馈调度策略,对进程进行分级(而不是简单的一个等待队列),进程运行时间长调度的优先级越低,每被抢占一次就下降一级。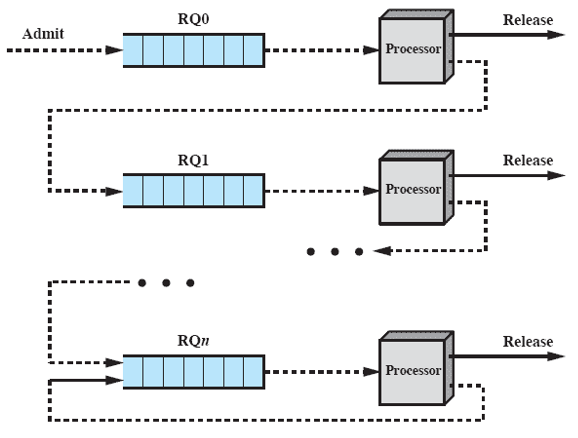
反馈调度往往会和前述的简单调度(比如FCFS或RR)结合使用,同时长进程周转时间会出现惊人的增加的现象(长进程多次被抢占,优先级不断下降,而长期得不到调度),所以会有一些相应的补偿措施(比如设置允许被抢占的次数,每当超过这个次数才会对进程进行降级操作)。
实时调度
嵌入式开发中还常见一些实时调度策略,与前述策略不同的时间,这些任务有最后期限的限制,这通常分为两种——一种是“硬实时”,要求必须满足最后期限的限制,否则将给系统带来不可接受的破坏或致命的错误(任务超时完成是无意义的);另一种是“软实时”,希望能够满足最后期限的限制,但并非强制(即使超时完成任务也有意义)。
拆解目标检测demo
前边介绍了进程、线程以及处理器调度的概念和简单的使用,接下来我们考虑如何将我们的目标检测demo拆解成两个线程以提高展示的流畅性。
我们的目标是将demo拆解成 目标检测 和 视频流获取和展示 两个线程,其中需要共享的数据包括 图像数据 和 检测结果 两部分(为了响应退出按钮,后续的示例程序还会额外增加一个作为退出标志的共享数据),每部分数据需要配备一把线程锁进行读写保护。
最终程序如下——
注意:这里不仅划分了线程,还针对不同线程的任务分配了cpu,比如RK3399上CPU0-3是四个小核,我们用来做视频流的获取、检测结果的标注和视频流的展示;CPU4-5是大核,我们用来做核心的目标检测任务。两个不同的线程使用不同的CPU核,互不冲突,合理地分配CPU对应用程序也会有一定的提升。
#include <unistd.h>
#include <iostream>
#include <iomanip>
#include <string>
#include <vector>
#include "opencv2/imgproc/imgproc.hpp"
#include "opencv2/highgui/highgui.hpp"
#include "tengine_c_api.h"
#include <sys/time.h>
#include <stdio.h>
#include "common.hpp"
#include <pthread.h> // 包含线程控制相关的库
#define DEF_PROTO "models/MobileNetSSD_deploy.prototxt"
#define DEF_MODEL "models/MobileNetSSD_deploy.caffemodel"
struct Box
{
float x0;
float y0;
float x1;
float y1;
int class_idx;
float score;
};
void get_input_data_ssd(cv::Mat img, float* input_data, int img_h, int img_w){
if (img.empty()){
std::cerr << "Failed to read image from camera.\n";
return;
}
cv::resize(img, img, cv::Size(img_h, img_w));
img.convertTo(img, CV_32FC3);
float *img_data = (float *)img.data;
int hw = img_h * img_w;
float mean[3]={127.5,127.5,127.5};
for (int h = 0; h < img_h; h++){
for (int w = 0; w < img_w; w++){
for (int c = 0; c < 3; c++){
input_data[c * hw + h * img_w + w] = 0.007843* (*img_data - mean[c]);
img_data++;
}
}
}
}
void post_process_ssd(cv::Mat img, float threshold,float* outdata,int num)
{
const char* class_names[] = {"background",
"aeroplane", "bicycle", "bird", "boat",
"bottle", "bus", "car", "cat", "chair",
"cow", "diningtable", "dog", "horse",
"motorbike", "person", "pottedplant",
"sheep", "sofa", "train", "tvmonitor"};
int raw_h = img.size().height;
int raw_w = img.size().width;
std::vector<Box> boxes;
int line_width=raw_w*0.002;
// printf("detect ruesult num: %d \n",num);
for (int i=0;i<num;i++){
if(outdata[1]>=threshold){
Box box;
box.class_idx=outdata[0];
box.score=outdata[1];
box.x0=outdata[2]*raw_w;
box.y0=outdata[3]*raw_h;
box.x1=outdata[4]*raw_w;
box.y1=outdata[5]*raw_h;
boxes.push_back(box);
// printf("%s\t:%.0f%%\n", class_names[box.class_idx], box.score * 100);
// printf("BOX:( %g , %g ),( %g , %g )\n",box.x0,box.y0,box.x1,box.y1);
}
outdata+=6;
}
for(int i=0;i<(int)boxes.size();i++){
Box box=boxes[i];
cv::rectangle(img, cv::Rect(box.x0, box.y0,(box.x1-box.x0),(box.y1-box.y0)),cv::Scalar(255, 255, 0),line_width);
std::ostringstream score_str;
score_str<<box.score;
std::string label = std::string(class_names[box.class_idx]) + ": " + score_str.str();
int baseLine = 0;
cv::Size label_size = cv::getTextSize(label, cv::FONT_HERSHEY_SIMPLEX, 0.5, 1, &baseLine);
cv::rectangle(img, cv::Rect(cv::Point(box.x0,box.y0- label_size.height),
cv::Size(label_size.width, label_size.height + baseLine)),
cv::Scalar(255, 255, 0), CV_FILLED);
cv::putText(img, label, cv::Point(box.x0, box.y0),
cv::FONT_HERSHEY_SIMPLEX, 0.5, cv::Scalar(0, 0, 0));
}
}
float outdata[15*6]; // 线程间共享变量——检测结果
cv::Mat frame; // 线程间共享变量——图像数据
int detect_num; // 线程间共享变量——检测结果
bool quit_flag = false; // 程序间共享变量——退出标志
graph_t graph;
// 与共享变量对应的线程锁
pthread_mutex_t m_frame, m_outdata, m_quit;
void *th_vedio(void *){
// 将线程绑定到cpu0-3上
cpu_set_t mask;
CPU_ZERO(&mask);
CPU_SET(0, &mask);
CPU_SET(1, &mask);
CPU_SET(2, &mask);
CPU_SET(3, &mask);
if (sched_setaffinity(0, sizeof(cpu_set_t), &mask) < 0) {
printf("Error: setaffinity()\n");
exit(0);
}
cv::VideoCapture capture(0);
capture.set(CV_CAP_PROP_FRAME_WIDTH, 960);
capture.set(CV_CAP_PROP_FRAME_HEIGHT, 540);
cv::namedWindow("MSSD", CV_WINDOW_NORMAL);
cvResizeWindow("MSSD", 1280, 720);
while(1){
pthread_mutex_lock(&m_frame);
capture >> frame;
pthread_mutex_unlock(&m_frame);
float show_threshold=0.25;
pthread_mutex_lock(&m_outdata); pthread_mutex_lock(&m_frame); // 上锁
post_process_ssd(frame, show_threshold, outdata, detect_num);
pthread_mutex_unlock(&m_outdata); // 解锁
cv::imshow("MSSD", frame);
pthread_mutex_unlock(&m_frame); // 解锁
if( cv::waitKey(10) == 'q' ){
pthread_mutex_lock(&m_quit); // 上锁
quit_flag = true;
pthread_mutex_unlock(&m_quit); // 解锁
break;
}
usleep(10000); // 注意必须sleep(不然太过频繁地取帧会影响检测线程的调度)
}
}
void *th_detect(void*){
// 将该线程绑定到cpu4-5上
cpu_set_t mask;
CPU_ZERO(&mask);
CPU_SET(4, &mask);
CPU_SET(5, &mask);
if (sched_setaffinity(0, sizeof(cpu_set_t), &mask) < 0) {
printf("Error: setaffinity()\n");
exit(0);
}
// input
int img_h = 300;
int img_w = 300;
int img_size = img_h * img_w * 3;
float *input_data = (float *)malloc(sizeof(float) * img_size);
int node_idx=0;
int tensor_idx=0;
tensor_t input_tensor = get_graph_input_tensor(graph, node_idx, tensor_idx);
if(!check_tensor_valid(input_tensor)){
printf("Get input node failed : node_idx: %d, tensor_idx: %d\n",node_idx,tensor_idx);
return NULL;
}
int dims[] = {1, 3, img_h, img_w};
set_tensor_shape(input_tensor, dims, 4);
prerun_graph(graph);
int repeat_count = 1;
const char *repeat = std::getenv("REPEAT_COUNT");
if (repeat)
repeat_count = std::strtoul(repeat, NULL, 10);
int out_dim[4];
tensor_t out_tensor;
while(1){
pthread_mutex_lock(&m_quit); // 上锁
if(quit_flag) break;
pthread_mutex_unlock(&m_quit); // 解锁
struct timeval t0, t1;
float total_time = 0.f;
for (int i = 0; i < repeat_count; i++){
pthread_mutex_lock(&m_frame); // 上锁
get_input_data_ssd(frame, input_data, img_h, img_w);
pthread_mutex_unlock(&m_frame); // 解锁
gettimeofday(&t0, NULL);
set_tensor_buffer(input_tensor, input_data, img_size * 4);
run_graph(graph, 1);
gettimeofday(&t1, NULL);
float mytime = (float)((t1.tv_sec * 1000000 + t1.tv_usec) - (t0.tv_sec * 1000000 + t0.tv_usec)) / 1000;
total_time += mytime;
}
std::cout << "--------------------------------------\n";
std::cout << "repeat " << repeat_count << " times, avg time per run is " << total_time / repeat_count << " ms\n";
out_tensor = get_graph_output_tensor(graph, 0,0);
get_tensor_shape( out_tensor, out_dim, 4);
pthread_mutex_lock(&m_outdata); // 上锁
detect_num = out_dim[1] <= 15 ? out_dim[1] : 15;
memcpy(outdata, get_tensor_buffer(out_tensor), sizeof(float)*detect_num*6);
pthread_mutex_unlock(&m_outdata); // 解锁
}
free(input_data);
}
int main(int argc, char *argv[])
{
const std::string root_path = get_root_path();
std::string proto_file;
std::string model_file;
int res;
while( ( res=getopt(argc,argv,"p:m:h"))!= -1){
switch(res){
case 'p':
proto_file=optarg;
break;
case 'm':
model_file=optarg;
break;
case 'h':
std::cout << "[Usage]: " << argv[0] << " [-h]\n"
<< " [-p proto_file] [-m model_file]\n";
return 0;
default:
break;
}
}
const char *model_name = "mssd_300";
if(proto_file.empty()){
proto_file = DEF_PROTO;
std::cout<< "proto file not specified,using "<< proto_file << " by default\n";
}
if(model_file.empty()){
model_file = DEF_MODEL;
std::cout<< "model file not specified,using "<< model_file << " by default\n";
}
// init tengine
init_tengine_library();
if (request_tengine_version("0.1") < 0)
return 1;
if (load_model(model_name, "caffe", proto_file.c_str(), model_file.c_str()) < 0)
return 1;
std::cout << "load model done!\n";
// create graph
graph = create_runtime_graph("graph", model_name, NULL);
if (!check_graph_valid(graph)){
std::cout << "create graph0 failed\n";
return 1;
}
// 初始化线程锁
pthread_mutex_init(&m_frame, NULL);
pthread_mutex_init(&m_outdata, NULL);
pthread_mutex_init(&m_quit, NULL);
// 创建线程
pthread_t id1, id2;
pthread_create(&id1, NULL, th_vedio, NULL);
pthread_create(&id2, NULL, th_detect, NULL);
// 等待线程
pthread_join(id1, NULL);
pthread_join(id2, NULL);
// 销毁线程锁
pthread_mutex_destroy(&m_frame);
pthread_mutex_destroy(&m_outdata);
pthread_mutex_destroy(&m_quit);
postrun_graph(graph);
destroy_runtime_graph(graph);
remove_model(model_name);
return 0;
}
在本文中,我们将尝试把视频的获取与展示和检测任务分离开来,分别放在两个不同的线程上工作,同时将不同的线程绑定到不同的cpu核上,使得两者的工作不会冲突。但在实际使用中你会发现,模型对于小目标的检测能力还是有所欠缺,下一篇文章我们将探究如何改善检测模型的小目标检测能力。