正则化技术
BGM:《命运石之门:负荷领域的既视感》主题曲
参考:
- 《Hands-On Machine Learning with Scikit-Learn and TensorFlow(2017)》Chap11
《Hands-On Machine Learning with Scikit-Learn and TensorFlow》笔记 - 《卷积神经网络——深度学习实践手册(2017.05)》
提前终止(Early Stopping)
每经过一定迭代次数之后将模型用于验证集上的评估,暂存、更新最近几次在验证集上有一定loss下降的模型;
当连续几次在验证集上没有出现明显的loss下降(甚至有可能回升)时终止训练;
提前终止通常表现的很好,如果和其他正则化技术共同使用可以获得更好的表现
L1、L2正则化
L2正则化:
又称权重衰减(weight decay)、岭回归(ridge regression)、Tikhonov正则化(Tikhonov regularization);
$$ l_2 = \frac{1}{2} \lambda ||\omega||^2_2 $$
其中 $\lambda$ 控制正则项大小,取值越大对模型复杂度的约束程度越大;
一般将该l2惩罚项加入到目标函数中,通过目标函数的误差反向传播;
L1正则化:
又称Elastic网络正则化;
$$ l_1 = \lambda ||\omega||_1 = \sum_i |\omega_i| $$
L1正则化不仅能够约束参数量级,还可以使参数稀疏化,使优化后部分参数置为0,并且也有去除噪声的效果;
L1和L2惩罚可以联合使用,如 $ \lambda_1 ||\omega||_1 + \lambda_2 ||\omega||_2^2 $
具体实现:
tensorflow中很多输出变量的函数(如 get_variable、fully_connected)都接受名为 *_regularizer 的参数进行正则化;
with arg_scope(
[fully_connected],
weights_regularizer=tf.contrib.layers.l1_regularizer(scale=0.01)): # 为fully_connected指定L1正则化
hidden1 = fully_connected(X, n_hidden1, scope="hidden1")
hidden2 = fully_connected(hidden1, n_hidden2, scope="hidden2")
logits = fully_connected(hidden2, n_outputs, activation_fn=None,scope="out")
注意在计算总的loss时要手动把正则化loss加上——
reg_losses = tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES)
loss = tf.add_n([base_loss] + reg_losses, name="loss")
dropout
论文:
【提出】Improving neural networks by preventing co-adaptation of feature detectors(2012)
【细节讨论】Dropout: A Simple Way to Prevent Neural Networks from Overfitting(2014)
核心思想:
在每一步训练中,所有神经单元(包含输入神经单元,但不包含输出神经单元)有一定概率p被忽略(但在预测时使用整个网络);
这里p称为dropout rate,通常取 $p=0.5$;
对应的还有一个keep probability,即 $q = 1 - p$;
每步训练时都有一部分单元缺失,使得每个单元都有机会在本次训练中占有一定地位,从而使得各个单元可以更好地从训练集中学习,使整个网络在工作时更有弹性;
部分“队友”的缺失、部分“输入数据”的缺失,在这种训练下,每个单元有更强的鲁棒性;
由于各个单元是一定概率q参与训练的,所以在需要对这些单元进行一定补偿——
- 可以在训练时,对每个单元的输出都除以q
- 也可以在预测时,为每个单元的输出都乘以q
这两种方式虽然不完全等价,但实际效果时差不多的
具体实现:
tensorflow提供专门的dropout层,默认时用第二种补偿方式;
from tensorflow.contrib.layers import dropout
# ...
is_training = tf.placeholder(tf.bool, shape=(), name='is_training')
keep_prob = 0.5
X_drop = dropout(X, keep_prob, is_training=is_training)
hidden1 = fully_connected(X_drop, n_hidden1, scope="hidden1")
hidden1_drop = dropout(hidden1, keep_prob, is_training=is_training)
hidden2 = fully_connected(hidden1_drop, n_hidden2, scope="hidden2")
hidden2_drop = dropout(hidden2, keep_prob, is_training=is_training)
logits = fully_connected(hidden2_drop, n_outputs, activation_fn=None, scope="outputs")
tensorflow提供了两个dropout(),一个在tensorflow.conrtib.layers包里,一个在tensorflow.nn包里——
前者在训练时有效,预测时失效;
后者在训练和预测时都是有效的;
所以一般来说,我们需要的是前者的dropout
如果说,在训练中加了dropout还是发现过拟合了,可以考虑增加dropout_rate(减小keep_prob);
缺点:
- dropout减缓了收敛的速度
- 而且,dropout对卷积层似乎没有作用(一般只用于全连接层)
参考 Why would I need to apply a dropout layer before a convolutional layer? | Quora
据说是因为卷积层参数数量远少于全连接层,一般不存在过拟合的问题;
大多数经典框架都只在全连接层上使用dropout,参考《经典的CNN分类架构 | Hey~YaHei!》
不过,
Dropout: A Simple Way to Prevent Neural Networks from Overfitting(2014)、FAST AND ACCURATE DEEP NETWORK LEARNING BY EXPONENTIAL LINEAR UNITS (ELUS)(2016)、92.45% on CIFAR-10 in Torch | Torch、Using convolutional neural nets to detect facial keypoints tutorial | danielnouri 等也对卷积层使用了dropout并有一定的提升;
也有一些关于对卷积层使用dropout或者dropout的变体的论文:
Towards Dropout Training for Convolutional Neural Networks(2015)、
Efficient Object Localization Using Convolutional Networks(2015)、
Analysis on the Dropout Effect in Convolutional Neural Networks(2016)
最大范数(Max-Norm)
每步训练之后,对权重w进行一定约束——
$$ w \gets w \frac{r}{||w||_2} $$
其中,r为超参数max-norm,$||w||_2$ 表示w的L2范数;
减小r将增加惩罚的力度,这将有助于抑制过拟合;
同时,如果没有使用BN层,那么max-norm也有抑制梯度消失与爆炸的作用;
具体实现:
tensorflow没有直接提供max-norm的操作:
# 借助tf.clip_by_norm构造max_norm操作
threshold = 1.0
clipped_weights = tf.clip_by_norm(weights, clip_norm=threshold, axes=1)
clip_weights = tf.assign(weights, clipped_weights)
with tf.Session() as sess:
# [...]
for epoch in range(n_epochs):
# [...]
for X_batch, y_batch in zip(X_batches, y_batches):
sess.run(training_op, feed_dict={X: X_batch, y: y_batch})
# 在每一步(训练一个batch)的最后手动调用一次max_norm的操作
clip_weights.eval()
如果有很多权重需要增加max_norm操作,那代码将变得十分冗余;
更加简洁的做法是自己构造一个Regularization——
def max_norm_regularizer(threshold, axes=1, name="max_norm", collection="max_norm"):
def max_norm(weights):
clipped = tf.clip_by_norm(weights, clip_norm=threshold, axes=axes)
clip_weights = tf.assign(weights, clipped, name=name)
tf.add_to_collection(collection, clip_weights) # 注意,这个clip_weights需要在外部使用,所以把它放入collection当中
return None # 不需要将loss加到整体的全局的loss上,所以只需要返回None
return max_norm
max_norm_reg = max_norm_regularizer(threshold=1.0)
hidden1 = fully_connected(X, n_hidden1, scope="hidden1", weights_regularizer=max_norm_reg)
# 取出collection中的clip_weights操作
clip_all_weights = tf.get_collection("max_norm")
with tf.Session() as sess:
# [...]
for epoch in range(n_epochs):
# [...]
for X_batch, y_batch in zip(X_batches, y_batches):
sess.run(training_op, feed_dict={X: X_batch, y: y_batch})
sess.run(clip_all_weights)
数据增强
人为修改训练集数据,达到扩充数据集的目的;
但这种修改必须是“可学习的”,比如添加白噪声是没意义的,因为白噪声不可学习;
比如做图片分类的时候,可以平移、旋转、缩放图片甚至改变亮度来做到数据增强,使得模型对图片的位置、角度、大小不那么敏感;
tensorflow提供了一些图片操纵的函数,可以从api中查到;
图像数据的扩充还可以参考 卷积神经网络CNN/数据扩充 | Hey~YaHei!
此外,还有通过混合训练数据来增强数据的手段,参考《深度学习小技巧(三):训练技巧 - 数据混合(Mixup) | Hey~YaHei!》
验证集的使用
验证集用于在训练阶段评测模型预测性能,一般在每轮(epoch)或每个批处理训练(step)后在训练集、验证集上分别做网络前向运算,绘制学习曲线,检验模型泛化能力;
比如图像分类准确率:
如图a,验证集准确率一直低于训练集准确率,无明显下降趋势,此时模型复杂度欠缺,是为欠拟合;
如图b,验证集准确率不仅低于训练集准确率,还有明显下降趋势,此时模型发生过拟合;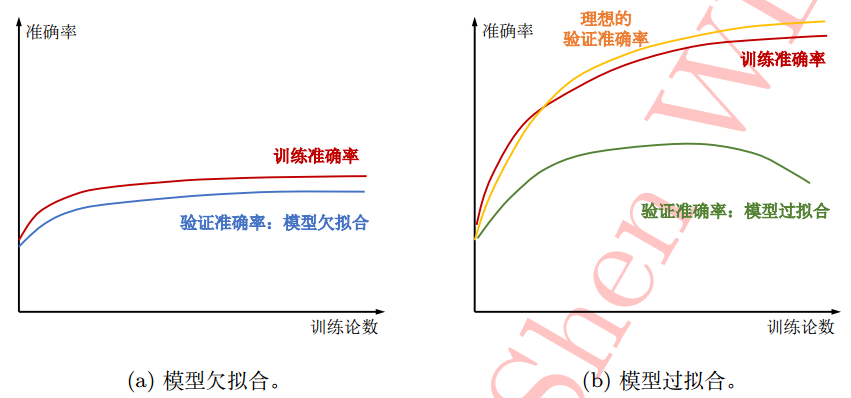
其他模型评估方法可参考 机器学习 - 周志华/Ch02 模型评估和选择 | Hey~YaHei!
以及 机器学习 - 吴恩达/2 过拟合与正则化技术 | Hey~YaHei!
其他
- 重叠池化(Overlapping Pooling)
《漫谈池化层 - 重叠池化| Hey~YaHei!》 - 随机池化(Stochastic Pooling)
《漫谈池化层 - 随机池化| Hey~YaHei!》 - 平滑标签(Label Smoothing Regularization, LSR)
《深度学习小技巧(三):训练技巧 - 平滑标签 | Hey~YaHei!》