CondConv:按需定制的卷积权重
最近正巧在看条件计算的东西,发现今年Google Brain发了一篇思路清奇的论文《CondConv: Conditionally Parameterized Convolutions for Efficient Inference(2019NeurIPS)》,这思路简直让人拍案叫绝,只可惜这种模型需要重新定制卷积算子才能有效发挥它的作用,如果没有工业界的推动想必短期内很难产生实用价值吧。
先来说说论文的主要贡献:条件计算、集成技术、注意力机制三者间极为巧妙的结合!
条件计算
如果是模型压缩是深度学习的一个边缘领域,那么条件计算一定是模型压缩里的边缘方向。如果你听过模型压缩,那你一定知道裁剪和量化,可能你还会知道一些紧凑网络的设计和知识蒸馏,但我打赌你十有八九没听过条件计算。
有一天我躺在床上睡觉,突然灵光一现——直观上讲,既然不同的layer乃至不同filter能提取出不同的特征,而对于不同的输入,我们所重视的特征必定也是不同的,是不是能设计出某个评估/预测模块从而智能地挑选合适layer、filter来计算而放弃无关layer、filter的计算呢?或者说当浅层特征足以完成推断,我们能不能提前从浅层特征图跳出而放弃后续深层特征的提取步骤呢?再或者,对于连续的视频流,有没有可能在浅层位置先预估出本帧图像的质量,从而判断是否放弃本帧图像的推断呢(比如有些视频流情况下我们不需要每一帧都做出准确推断的时候,能否提前中断来获取新的可能质量更好的一帧图像)?
这种思路似乎有些诡异,但又有些合理。正当我为自己“天才般”的想法沾沾自喜的时候,发现其实很早以前就有人研究过这类问题(好吧QAQ)——
第一种思路通常被称为条件计算(Conditional Computation),属于模型压缩里比较冷门的一个小方向;
第二种思路被称为提前终止(Early Stop),跟条件计算稍微有些类似;
第三种思路好像没看到相关文献,不过想想似乎有些麻烦,比如我该怎么评估一份特征图质量的“好坏”??
简单来说,条件计算是构建一种动态的网络结构,每次推断的时候先由决策网络(或模块)根据模型输入(甚至每一层的输入)推断出所要使用网络部件,然后利用原始网络的一个子集完成实际的推断过程。
举几个典型的例子:
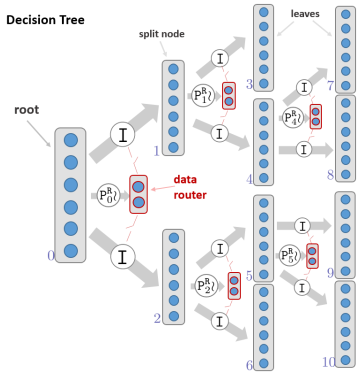
- 《Decision Forests, Convolutional Networks and the Models in-Between(2016)》使用决策树进行分支判断,从而使用有限的网络结构完成一次次推断任务
《BlockDrop: Dynamic Inference Paths in Residual Networks(2018CVPR)》设计一个独立的决策网络,根据模型输入的图片来挑选有限的block完成ResNet的实际推断
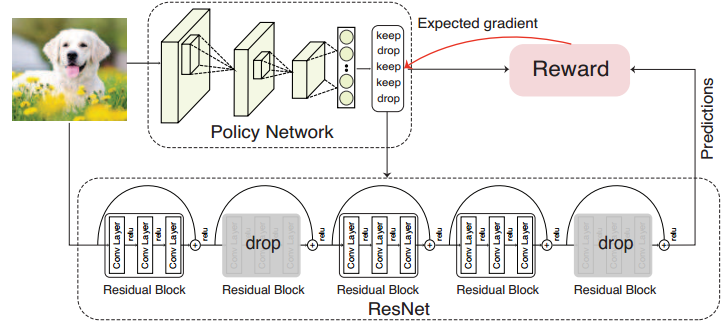
该方法效果存疑——
按照作者开源的代码blockdrop | github, Tushar-N报告的效果,
ResNet101-BlockDrop的Top1准确率为76.4%,计算量为12.5GFLOPS;
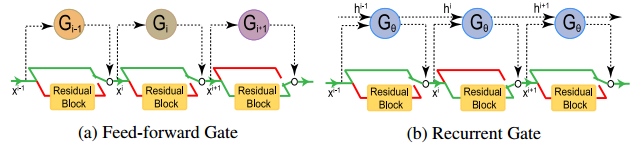
然而即使最原始的ResNet101_v1,却也能在7.6GFLOPS计算量下达到78.25%的Top1准确率,不知道作者这是什么迷惑操作QAQ。- 《SkipNet: Learning Dynamic Routing in Convolutional Networks(2018ECCV)》为每个block添加一个额外的评估模块,根据block的输入来判断是否跳过残差支路的计算过程
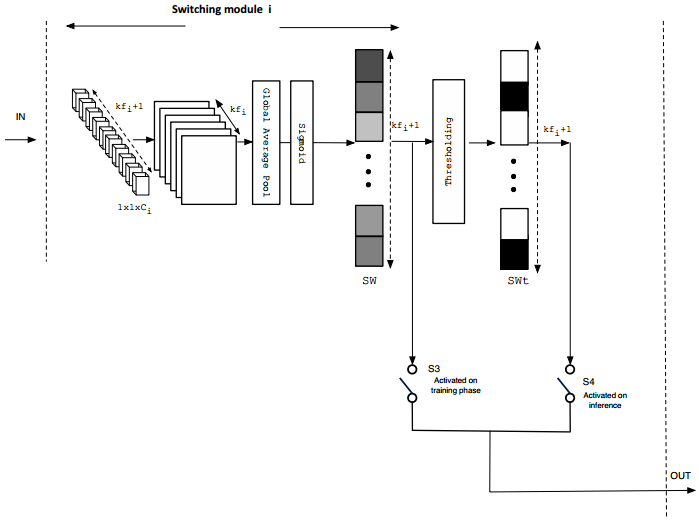
- 《Parsimonious Inference on Convolutional Neural Networks: Learning and applying on-line kernel activation rules(2017)》为每个卷积层设计一个LKAM模块,根据卷积层的输入特征图判断需要启用哪几个Filter
看着思路好像挺简单,但是不得不承认,训练这样一个模型实在不容易——我做过几个简单的实验,决策网络或决策模块往往很容易倾向于直接“杀死”某个block、layer、filter让它“永世不得翻身”于是决策网络相当于沦为传统裁剪的一个辅助任务。。。总之,经常训出来的决策网络就不大聪明的亚子。
集成技术
- 模型集成
最简单的模型集成是针对相同的任务、相同的输入设计几个不同的网络(甚至有的时候直接取训练过程中的若干checkpoint,这种集成方法称为快照集成,使用简单,通常也会结合模拟退火来确保不同的“专家”能够具备差异化的知识),最后再推断阶段分别将同一个输入投喂给所有“专家”,然后组合他们的输出来得出结论——比如最简单的组合方式可以采取举手表决。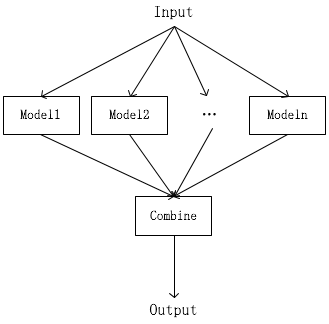
- 分支集成
模型集成的规模往往有些庞大,退而求其次我们可以共享一部分浅层特征,然后产生若干分支,最后融合各分支提取的特征达到集成的目的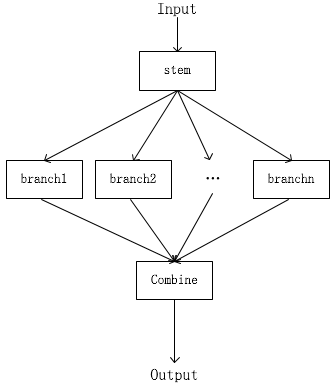
- 带条件计算的分支集成
有的时候可能有的分支的“小专家”对一些样本不太擅长,我们可以选择不听取他们的意见,论文《HydraNets: Specialized Dynamic Architectures for Efficient Inference(2018CVPR)》就把条件计算跟分支集成结合了起来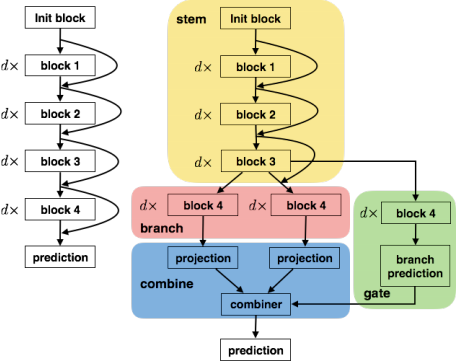
无论哪种集成技术,都免不了模型规模(包括参数量和计算量)会产生成倍的增长,往往需要付出很大的代价才能取得些微的提升。在我看来,集成技术并没有太大的实用价值,只不过比赛通常不重视模型规模的影响,所以大家一味追求高准确率而堆叠模型罢了。不过,集成也非一无是处,既然有一个甚至很多个聪明的专家,尽管他很庞大,但却是一位不错的老师,利用知识蒸馏技术将集成模型的知识蒸馏到常规的模型上或许也是一个不错的思路。
CondConv
核心思想
CondConv的核心思想是带条件计算的分支集成的一种巧妙变换,首先它采用更细粒度的集成方式,每一个卷积层都拥有多套权重,卷积层的输入分别经过不同的权重卷积之后组合输出:
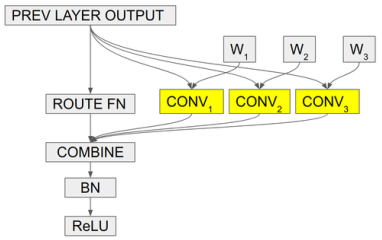
但这计算量依旧很大,既然输入相同,卷积又是一种线性计算,如果COMBINE也是一个线性计算(比如加权求和)……那有趣的事情就发生了——
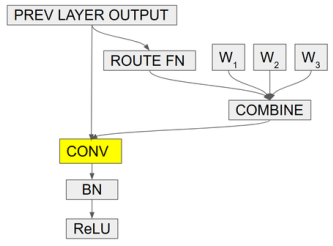
作者将多套权重加权组合之后,只做一次卷积就能完成相当的效果!
简单来说,CondConv在卷积层设置多套卷积核,在推断时对卷积核施加SE模块,根据卷积层的输入决定各套卷积核的权重,最终加权求和得到一个为该输入量身定制的一套卷积核,最后执行一次卷积即可。
事实上作者只使用了一层全连接,而不是标准的SE模块~
- 从注意力机制的角度上看,这里将注意力机制应用到了卷积权重上
- 从条件计算的角度上看,这里利用注意力机制为多套卷积核产生了对应权重,最终加权求和,是一种soft gate的方案
- 从集成技术的角度上看,卷积层集成了若干套卷积核的知识,而且只需要付出少量的额外计算代价,当然内存依旧会爆炸式增长,但通常相对于计算力来说,内存是相当易得的
这不得不说是一种令人拍案叫绝的巧妙思路!!!!
效果
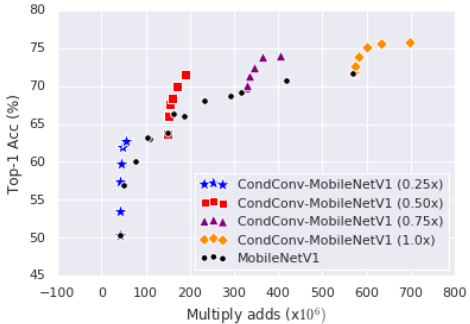
作者用MobileNetv1进行实验,对0.25x、0.5x、0.75x、1.0x分别使用1、2、4、8、16、32个experts——
训练技巧
虽然好用,但这模型训起来稍微有些麻烦(麻烦指的是训练过程会比较慢,超参应该还是比较好调的),有两种训练方式——
- 使用
batch_size=1的训练,每次前传都先组合权重再进行卷积 - 使用
batch_size>1的训练,每次前传都直接分别卷积,最后在做组合
两种计算过程基本是等效的,但考虑到深度学习框架大多对大batch的训练过程有比较充分的优化,所以作者建议当experts数量不多余4时,采用方法2,超过4之后采用方法1.不过值得一提的是,BN层在batch_size比较小时是不利的,此时最好改用其他Normalization层。