2019中兴捧月·初赛
赛题背景
自从 Alex Krizhevsky 夺得 ILSVRC 2012 ImageNet 图像分类竞赛的冠军后,深度卷积神经网络在图像分类、物体检测、语义分割、目标跟踪等多个计算机视觉任务中均取得优秀表现,更有甚者在某些领域超越人眼的精度,但在其不断逼近计算机视觉任务的精度极限的同时,其深度和尺寸也在成倍增长,随之而来的较高的设备资源占用、较低计算效率等问题,使其只能在有限的平台下使用,难以移植到移动端和嵌入式芯片当中,因此模型小型化与加速成了亟待解决的问题。本竞赛旨在针对一个给定的深度卷积网络,在不进行深度卷积网络调优训练的条件下,不限定优化的方式,输出新的网络模型,达到降低模型大小,降低运行态设备资源占用,提高运行速度的效果。
评分细则:
$$Score = {\frac{X-x}{X} \times 20 + \frac{Y-y}{Y} \times 80} \times A(z)$$
$$\mathbf { A } ( \mathbf { z } ) = \left\{ \begin{array} { c l } { \mathbf { 1 } , } & { \mathbf { 0 . 9 8 } \leq \mathbf { z } \leq \mathbf { 1 } } \\ { 0.95 , } & { 0.95 \leq \mathbf { z } < 0.98 } \\ { 0.9 , } & { 0.9 \leq \mathbf { z } < 0.95 } \\ { \mathbf { 0 } , } & { \mathbf { z } < \mathbf { 0 } .9 } \end{array} \right.$$
其中,$X$、$Y$分别为原始模型的显存占用大小和推理时间,$x$、$y$、$z$分别为优化后的显存占用大小、推理时间、与原始输出的平均余弦距离(1000张测试图片)。
压缩方案
安全操作
首先进行一些简单的、接近无损的压缩优化操作。
层融合
通常而言,两个连续的线性操作是可以合并的,而Convolution和BatchNorm的融合是最典型的例子,只需要简单的数学计算就能将BathchNorm的计算过程融合到Convolution中。更多细节可以参见:《MobileNet-SSD网络解析 - BN层合并 | Hey~YaHei!》
具体代码参考:merge_bn | github, YaHei
清除闲置、无效的Filter
论文《Pruning Filters for Efficient Convnets(2017-ICLR)》指出,可以通过计算Filter的L1范数(即绝对值之和)来衡量Filter的重要性。
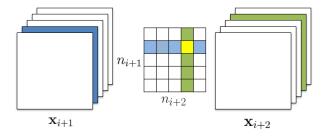
在这个思路的基础上,我们可以计算每个Filter绝对值的平均值(规范化数值,避免Filter大小不一带来的影响),并设置一个极小的阈值(如1e-5)来对Filter进行裁剪,同时由于卷积的输出通道减少,后续卷积层对应的Kernel也可以随之剔除(全连接层类似)。
具体代码参考:clear_idle_filters | github, YaHei
更换Caffe的Backend
BLVC/Caffe-gpu为Convolution、Pooling、ReLU等提供了Caffe、cuDNN两种Backend,可以通过prototxt的engine参数来指定,而比赛模型默认使用的是cuDNN。首先可以将所有engine替换为Caffe,借助caffe-time工具比较替换前后各层的推理速度,可以发现大多数卷积和ReLU用Caffe作为Backend推理耗时更短,但也存在例外。
分析
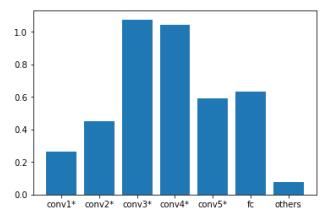
从模型上看,Conv1*是一个类似inception的结构;Conv2*是一个类似VGG的卷积堆叠同时加上了Concat的跨层特征融合;Conv3*、Conv4*、COnv5*均为残差结构。但值得注意的是,Conv5*竟然全都是1x1卷积,可以猜测Conv5*很可能没学到多少东西。
耗时概览
本次比赛显存优化、速度优化分数占比分别为20%和80%,显然速度优化更为重要,先用caffe-time工具测试各层的推理速度,然后用python解析caffe-time工具的输出获取模型各结构的耗时情况:
Filters分析
将所有卷积核沿Filter方向求取绝对均值,绘制成直方图,观察卷积输出通道的重要性;
Kernels分析
将所有卷积核沿Kernel方向求取绝对均值,绘制成直方图,观察卷积输入通道的重要性;
Feature Maps分析
由于本次比赛没有提供数据集,但告知了数据的处理方式(减去127.5并除以128),故向模型投喂随机样张,统计各通道的失活率(输出值为0的概率);
参考论文:《Network Trimming: A Data-Driven Neuron Pruning Approach towards Efficient Deep Architectures(2016)》
有损的压缩优化
从先前的分析可以了解到,残差由于其结构的特殊性不易裁剪压缩,但有趣的是 conv5*使用了大量的 1x1 卷积,而且从filters上看conv5*存在大量低效的通道,而 feature maps 也显示 conv5*各输出通道普遍有极高的失活率, 加上 conv5*与全连接层相邻,显然 conv5*具备极大的压缩优化空间;而 conv3*、 conv4*在 filters、 kernels、 feature maps的分析上则显得很紧凑,似乎可操作空间非常小。除了残差外, conv1*、 conv2*这些只由 Convolution 和 Concat 组成的结构还是有一些压缩优化空间的。
Block Prune - conv5*
按理说,不经过重训练直接丢弃整个block是很危险的,但从先前的分析,尤其是在Feature Map上可以看到,Conv5*的存在相当的多余。
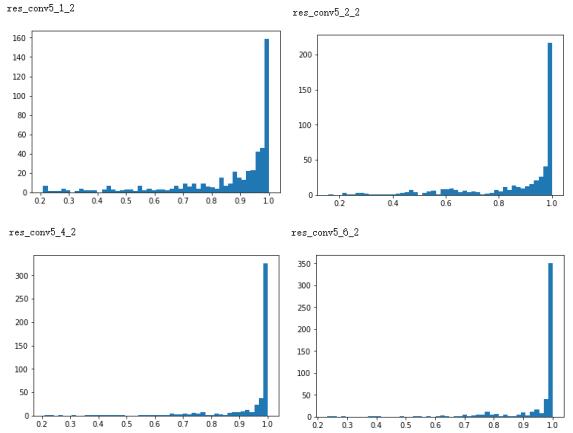
可以看到res_conv5_4_2和res_conv5_6_2的输出通道都有极高的失活率,而res_conv5_1_2和res_conv5_2_2的失活率也不低。加之丢弃block的操作十分诱人——不仅少了一整个block的计算量,又少了层与层之间的延迟;不仅如此,Conv5*之后紧连着全连接层,如果能够同时丢弃conv5_3*、conv5_4*或者conv5_5*、conv5_6*,那么全连接层的神经元数量也可以大幅减小。
- 首先尝试丢去conv5_3*、conv5_4*、conv5_5*、conv5_6*,可以看到线上的z值仅下降到0.983(此时甚至还没有被惩罚);
- 继续丢去conv5_2*,线上z值还有0.972(低于0.980,有5%的总分惩罚);
- 再继续丢去conv5_1*,线上z值则骤减;但如果只保留conv5_1_1b,线上z值依旧还有0.947;
显然丢弃conv5_3*、conv5_4*、conv5_5*、conv5_6*是极其有利的,此时由于残差的shortcut结构,Concat的三个bottom全指向了res_conv5_2_2,那么不妨直接取消Concat,并将全连接层的三组权重(分别对应每一个bottom)直接叠加得到新的权重,极大地减小了全连接层的计算量和参数量;
虽然只丢弃conv5_3*、conv5_4*、conv5_5*、conv5_6*所取得的z值可以避免惩罚,但考虑到其他有损的压缩优化还能进一步提升,死守0.980似乎没有必要,因此conv5_2*也可以果断丢弃,而conv5_1*损失较大,不宜随便丢弃。
Layer Prune - conv2*
受先前conv5*的block prune启发,发现其实conv2*也明显存在类似的情况。
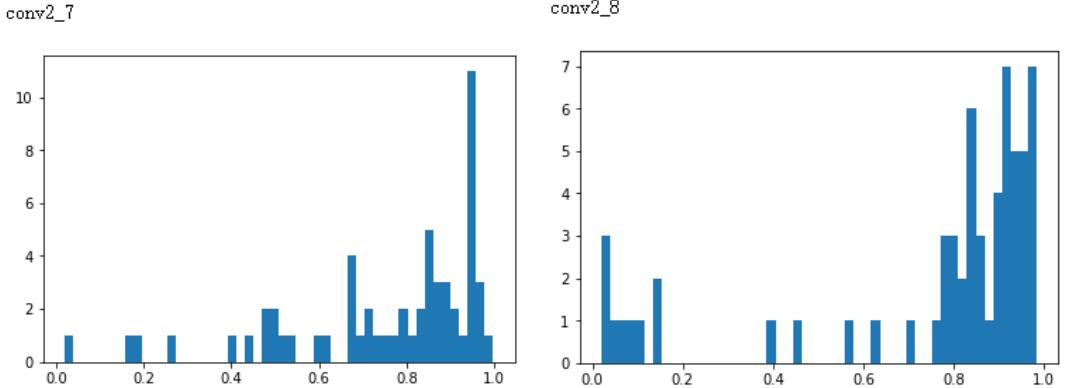
失活率整体靠右, 同时在后述的逐通道试裁和随机搜索中发现, conv2_7 和 conv2_8确实表现的十分多余, 尝试丢弃后线上 z 值也仅从 0.983 下降到 0.977,不仅丢弃了两层的计算量, Concat 后的 conv3_1_1 和 conv3_1_1b 也获益不少。
奇异值分解(SVD) - 全连接层
用 SVD 将一层全连接层分解为两个全连接层串联,通过对权重作奇异值分解可以绘制出 sigma 的累加曲线——
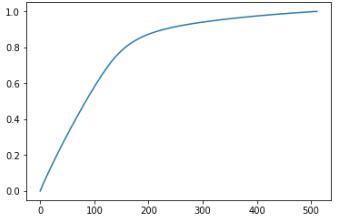
可以看到当 r 值比较大的时候, sigma 累加值占整体求和值的比例都很高,当低于某个值后则开始迅速下降,大致推测最佳收益的 r 值大概在 180-200 附近(实际操作中如果有多余的 z 值可供挥霍,下降至 140、 150 附近也是可行的)。
Channel Prune
通道裁剪的关键在于找到合适的衡量通道重要性的标准,如——
- 从输出通道的角度,计算Filter的绝对均值;
- 从输入通道的角度,计算Kernel的绝对均值;
- 输入样张,统计输出特征图的失活率;
- 用SVD的U矩阵作为作为通道重要性的参考;
- 逐通道试裁:逐一删除通道,并在本地测试对模型精度的影响;
- 随机搜索可裁剪通道:每次挑选一个或一组通道裁剪,并在本地测试对精度的影响,若输出损失足够小,则使裁剪生效,否则回溯
- ……
注意方法3、5、6依赖于测试数据,由于比赛中实际的数据集不明确,其裁剪结果只具备一定的参考价值,不宜全盘接受。
一些提升不明显的小手脚
不同分支卷积合并计算后切片
观察 conv1*可以发现 data 被 split 成三份分别送往 conv1_1_1、 conv1_2_1 和conv1_3_1,而且 conv1_1_1 和 conv1_3_1 是完全相同的卷积计算(kernel_size=3,stride=2, pad=1),故可以将两者合并运算后再切片分别送往下一级,虽然 slice 增加了额外的开销,但由于卷积合并运算总体耗时反而有少量的下降:
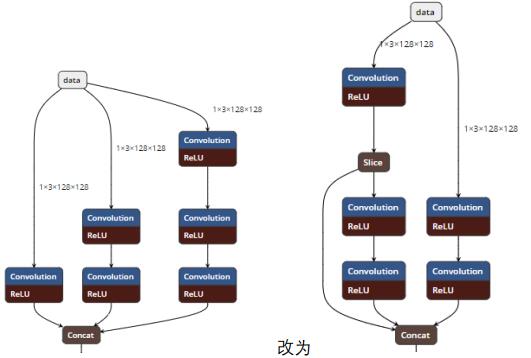
相同分支的卷积合并
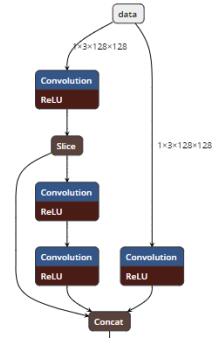
做过空闲通道裁剪之后, conv1_2_1 的卷积输出通道仅为 2,显然计算过程中 GPU 上会有大量的 ALU 空闲,事实上并不友好。有趣的是, conv1_2_1 的 feature maps显示,其失活率极低(两个通道的失活率分别为 0.1%和 0.37%),也就是说非线性层 ReLU 在这作用不大,可以直接丢弃——那么 conv1_2_1 和 conv1_2_2 两个线性层就直接相连了。众所周知,相邻线性计算是可合并的(典型的如 Convolution 和 BatchNorm),故将 conv1_2_1 和 conv1_2_2 合并为 5x5 卷积,虽然表面上 MAC 增加了(2.5M=>4.6M),但由于层延迟的减小和并行度的增加,反而在整体上有了微小的提升。这里注意到两个 3x3 卷积都是带 padding 的,合并到 5x5 卷积后边缘部分的计算结果会和原始结果有较大出入,但所幸此处特征图尺寸高达 128x128,而且层的位置较浅,该误差就几乎可以忽略不计了。conv1*变为——
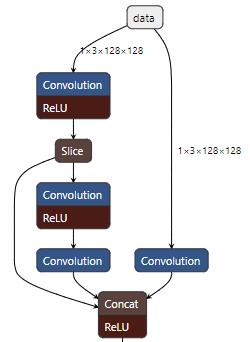
推迟ReLU
conv1_2_2和conv1_3_3都需要ReLU后再传递给Concat,既然如此为什么不直接把ReLU直接推迟到Concat之后一口气做呢?
后记
就模型优化学习而言,我也算是个新手(在这方面,以前只做过简单的线性量化),一开始我只懂得层融合,经过不断地查阅资料、尝试,慢慢挤进第一梯队,再后来运气好通过修改engine一跃到榜首。之后不断有人私戳我与我交流,从大佬们那学来了不少小技巧,学会SVD、学会裁剪等等……整个初赛阶段通过交流、实践使自己的能力和成绩不断提升,受益匪浅。