复用预训练层
BGM:《Megalo Box》ED
NakamuraEmi的歌有种说不出来的特别
参考《Hands-On Machine Learning with Scikit-Learn and TensorFlow(2017)》Chap11
《Hands-On Machine Learning with Scikit-Learn and TensorFlow》笔记
迁移学习(transfer learn)
如果已经训练好了一个网络(如可以识别猫、狗等动物),如果需要训练一个新的类似任务的网络(如只识别猫),可以直接使用已有网络的一部分底层,在这些层的基础上加几个层,训练时固定复用层的权重,只训练新加的几个层;
- 可以加速训练过程
- 可以使用较小的训练集
- 但是要求新网络的输入数据大小与复用网络的输入数据大小保持一致
- 仅适用于数据的低层次特征相类似的任务
- 任务越接近,可以复用的底层越多;甚至非常接近的任务,可以只替换output层
- 如果需要进一步fine-tune,可以在充分训练新加的几个层之后,再整体训练一段时间(复用层的权重也参与训练)
复用tensorflow模型
如果复用整个模型,直接用 tf.Saver 的 restore 方法即可;
如果只复用模型的一部分,可以借助 tf.get_collection 函数——
# 创建初始化op
init = tf.global_variables_initializer()
# 创建收集op
# ... 第一个参数为key,指明获取哪些对象;key在tf.GraphKeys中有一系列定义(这里表示获取可训练的变量)
# ... 第二个参数为scope,接受一个正则表达式,作为一个过滤器来筛选特定scope的对象
# ...... 这里表示获取名为hidden1, hidden2, hidden3的三个scope中的所有对象
# ... 返回一个对象名称组成的列表
reuse_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope="hidden[123]")
# 创建一个用于读取原模型的Saver
# ... tf.train.Saver的第一个参数为var_list,接受一个字典(一系列键值对)
# ...... 在restore时,只从原模型中读出名字与键对应的对象,并且在当前模型中命名为值
reuse_vars_dict = dict([(var.name, var.name) for var in reuse_vars])
original_saver = tf.Saver(reuse_vars_dict)
# 创建优化器和训练op
# ... 只训练hidden4和输出层,而固定(freezing)hidden[123]的权重
# ...... 此时hidden[123]称为frozen layers
# ... tf.get_collection获取需要训练的变量列表,并将列表传递给优化器来指定训练的变量
train_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope="hidden4|outputs")
training_op = optimizer.minimize(loss, var_list=train_vars)
# 创建一个用于保存新模型的Saver
new_saver = tf.Saver()
with tf.Session() as sess:
sess.run(init)
original_saver.restore("./my_original_model.ckpt")
# .....训练略sess.run(training_op).....
new_saver.save("./my_new_model.ckpt")
复用其他框架的模型
- 用其他框架的API获得其模型下的权重
- 创建相应的placeholder占位符
- 创建相应的网络结构
- 创建op操作,将placeholder赋值给网络结构里的权重变量
- session运行时将已有权重投喂给placeholder
加速训练:复用frozen层的输出结果(牺牲空间)
由于frozen层权重固定,对一个训练集来说,每一组训练数据在frozen层的最终输出是固定的;
训练时我们往往需要在重复的数据上训练很多趟,所以如果记录下frozen层的最终输出,
可以避免数据在frozen层进行重复计算,从而达到加速训练的目的,
但相应地会占据大量的内存空间(取决于数据集大小和frozen最后一层输出的大小)
具体实现——
# ... 假设hidden[123]固定,训练hidden4和outputs ...
n_epochs = 100
n_batches = 500
with tf.Session() as sess:
# 先投喂整个数据集来获得frozen层的最终输出
hidden3_outputs = sess.run(hidden3, feed_dict={X: X_train})
# 分趟训练
for epoch in range(n_epochs):
# 获取打乱的训练数据索引集(permutation相当于arange和shuffle的混合)
shuffled_idx = np.random.permutation(len(hidden3_outputs))
# 构造本趟训练的batch,这里不再直接使用训练集作为输入,而是从前边计算好的hidden3的输出直接输入给下一层
# ... np.array_split将一个列表等分成若干份
# ...... np.array可以给定一个索引列表,从中抽取出对应索引的元素组成一个新的列表
# ...... 如:
# ......... a = np.arange(10)
# ......... a[[0,2,4,6]]
# ......... >> array([0,2,4,6])
hidden3_batches = np.array_split(hidden3_outputs[shuffled_idx], n_batches)
y_batches = np.array_split(y_train[shuffled_idx], n_batches)
# 对各个batch依次进行训练
for hidden3_batch, y_batch in zip(hidden3_batches, y_batches):
sess.run(training_op, feed_dict={hidden3: hidden3_batch, y: y_batch}) # 直接向hidden3投喂数据
np.random.permutation 和 np.random.shuffle的区别:https://blog.csdn.net/u010099080/article/details/73395601
… shuffle只接受list,然后打乱list内的元素并返回
… permutation既接受list也接受int
…… 如果是list,相当于shuffle( list )
…… 如果时int,相当于shuffle( arange(int) )
Model Zoos
Tensorflow提供了很多现成了主流网络模型,都包含在 tensorflow.contrib.slim.python.slim.nets 包中;
tensorflow/models:
https://github.com/tensorflow/models
caffe提供了更全面的主流网络模型:
https://github.com/BVLC/caffe/wiki/Model-Zoo
Saumitro Dasgupta写了一个转换器,可以方便地将caffe网络转换为tensorflow网络模型:
https://github.com/ethereon/caffe-tensorflow
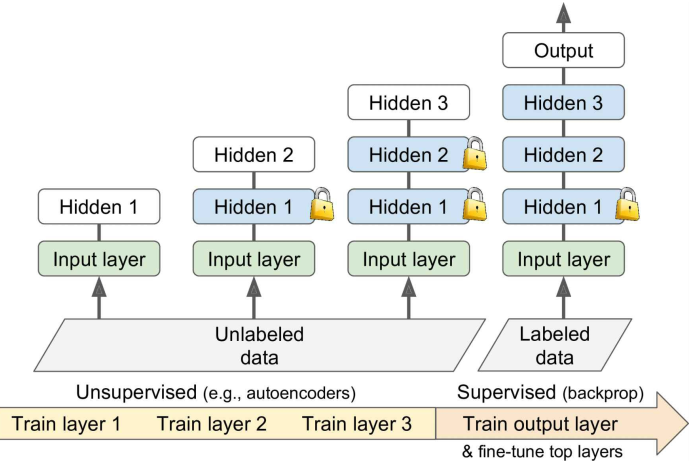
无监督预训练
如果有一个训练任务,没有类似任务的现成模型可以复用,只有少量标注好的数据和大量未标注的数据,可以——
- 继续标注数据
- 如果标注繁琐或者成本过高,可以使用无监督预训练的方式【如用自编码器作无监督预训练】
论文:Why Does Unsupervised Pre-training Help Deep Learning?(2009)
使用无监督训练,从底层开始逐层训练各个隐藏层,每次只训练一个层而固定其他层的权重;
无监督训练可以使用Restricted BoltzmannMachines (RBMs)、autoencoders等,目前autoencoders用的更多些;
最后用监督训练的方式,fine-tune较高的layers:
- 寻找一个训练数据易收集且易标注的类似任务,先训练出一个模型来复用给这个任务
- 在辅助任务上进行预训练,比如:
- 想训练一个人脸识别的模型,为每一个注册者获取上百张人脸照片是不切实际的。
可以先获取大量随机人脸的照片,训练一个模型来检测两张人脸图片是否对应同一个人;
该任务得到一个比较好的特征检测器,复用该任务的底层权重,进而用少量数据来训练出特定人脸的识别模型 - 想为某个语言处理任务训练一个模型。
可以先获取大量的语句,训练一个分辨语法是否正确的模型。
(比如说把这些语句先都标记为good,然后打乱语序标记为bad进行训练)
该任务得到一个有一定语言能力的模型,复用该任务的底层权重,进而用少量数据来训练目标任务的模型 - Max Margin Learning,训练一个打分模型
SVM就是基于Max Margin Learning的一种分类器
为预测结果进行打分,用损失函数来训练一个模型,使得预测的好结果比坏结果的分数高于某个阈值
- 想训练一个人脸识别的模型,为每一个注册者获取上百张人脸照片是不切实际的。